[OpenAIBlog19] Language Models are Unsupervised Multitask Learners (GPT-2) [porject]
- GPT-2 is a large transformer-based language model, which is trained with a simple objective: predict the next word, given all of the previous words within some text
- GPT-2 is a direct scale-up of GPT, with more than 10X the parameters and trained on more than 10X the amount of data
- We demonstrate language models can perform down-stream tasks in a zero-shot setting – without any parameter or architecture modification
- It should model p(output|input, task), which has been variously formalized in multitask and meta-learning settings
- Get surprising results without any fine-tuning of GPT-2 models on some language tasks like question answering, reading comprehension, summarization, and translation
[NAACL19] BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model [demo]
- We show that BERT (Devlin et al., 2018) is a Markov random field language model.
- Compared to the generations of a traditional left-to-right language model, BERT generates sentences that are more diverse but of slightly worse quality
- Because the model expects context from both directions, it is not immediately obvious how BERT can be used as a traditional language model
- BERT is a combination of a Markov random field language model (MRF-LM, Jernite et al., 2015; Mikolov et al., 2013) with pseudo loglikelihood (Besag, 1977) training
- We can use BERT to compute the unnormalized log-probabilities log φt(X) to find the most likely sentence within the set.
- We experiment with generating from BERT in a left-to-right manner.
- Three functions:
- parallel_sequential_generation:Generate for one random position at a timestep
- parallel_generation: Generate for all positions at each time step
- sequential_generation: Generate one word at a time, in L->R order
def sequential_generation(seed_text, batch_size=10, max_len=15, leed_out_len=15,
top_k=0, temperature=None, sample=True, cuda=False):
""" Generate one word at a time, in L->R order """
seed_len = len(seed_text)
batch = get_init_text(seed_text, max_len, batch_size)
# [[CLS], [MASK], [MASK], ..., [MASK], [SEP]] * batch_size
for ii in range(max_len):
inp = [sent[:seed_len+ii+leed_out_len]+[sep_id] for sent in batch]
inp = torch.tensor(batch).cuda() if cuda else torch.tensor(batch)
out = model(inp)
idxs = generate_step(out, gen_idx=seed_len+ii, top_k=top_k, temperature=temperature, sample=sample)
# find the best word from top-k choice
for jj in range(batch_size):
batch[jj][seed_len+ii] = idxs[jj]
return untokenize_batch(batch)
comment:
- This paper mathematically explained why BERT can be used as a generator
- But the generation method is obvious and trivial
- The “wild” generation is in an unsupervised manner and could not serve the machine translation task or text summarization task
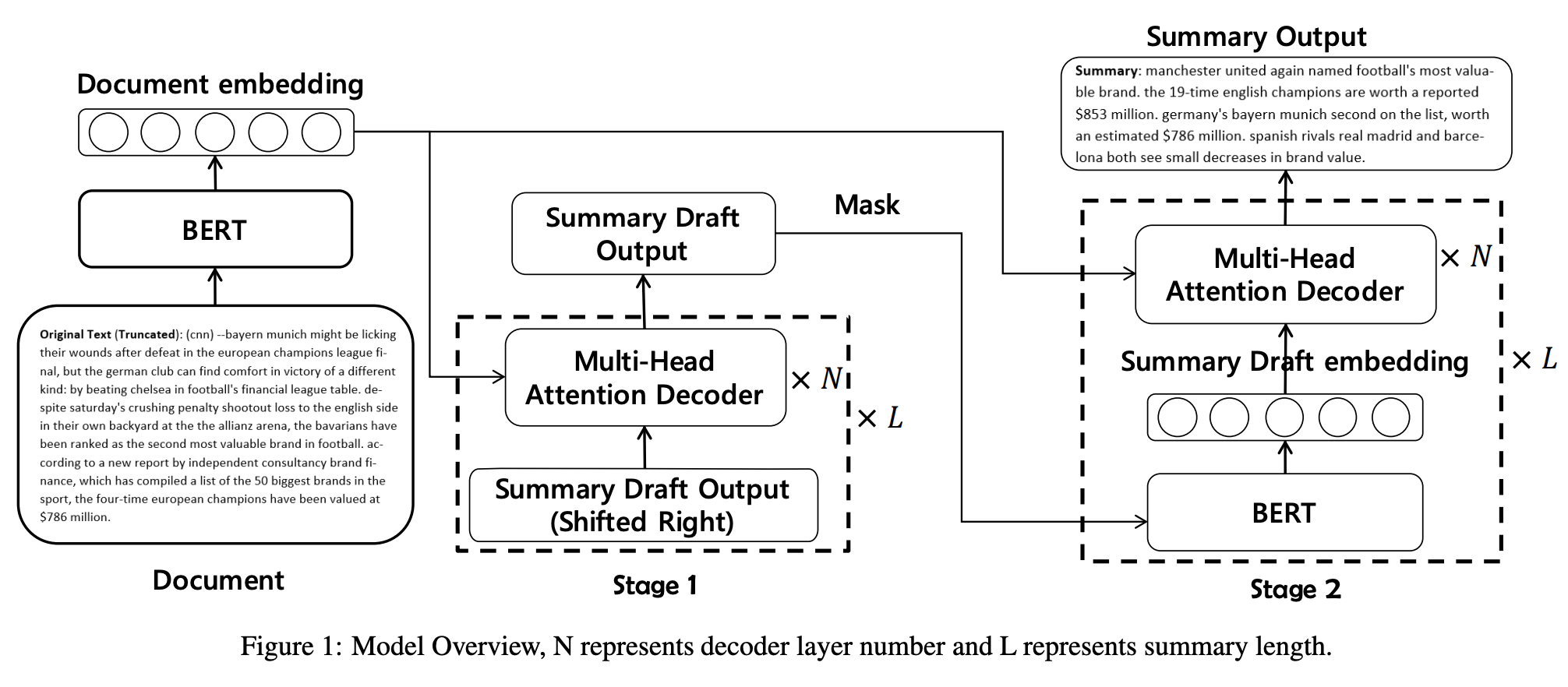
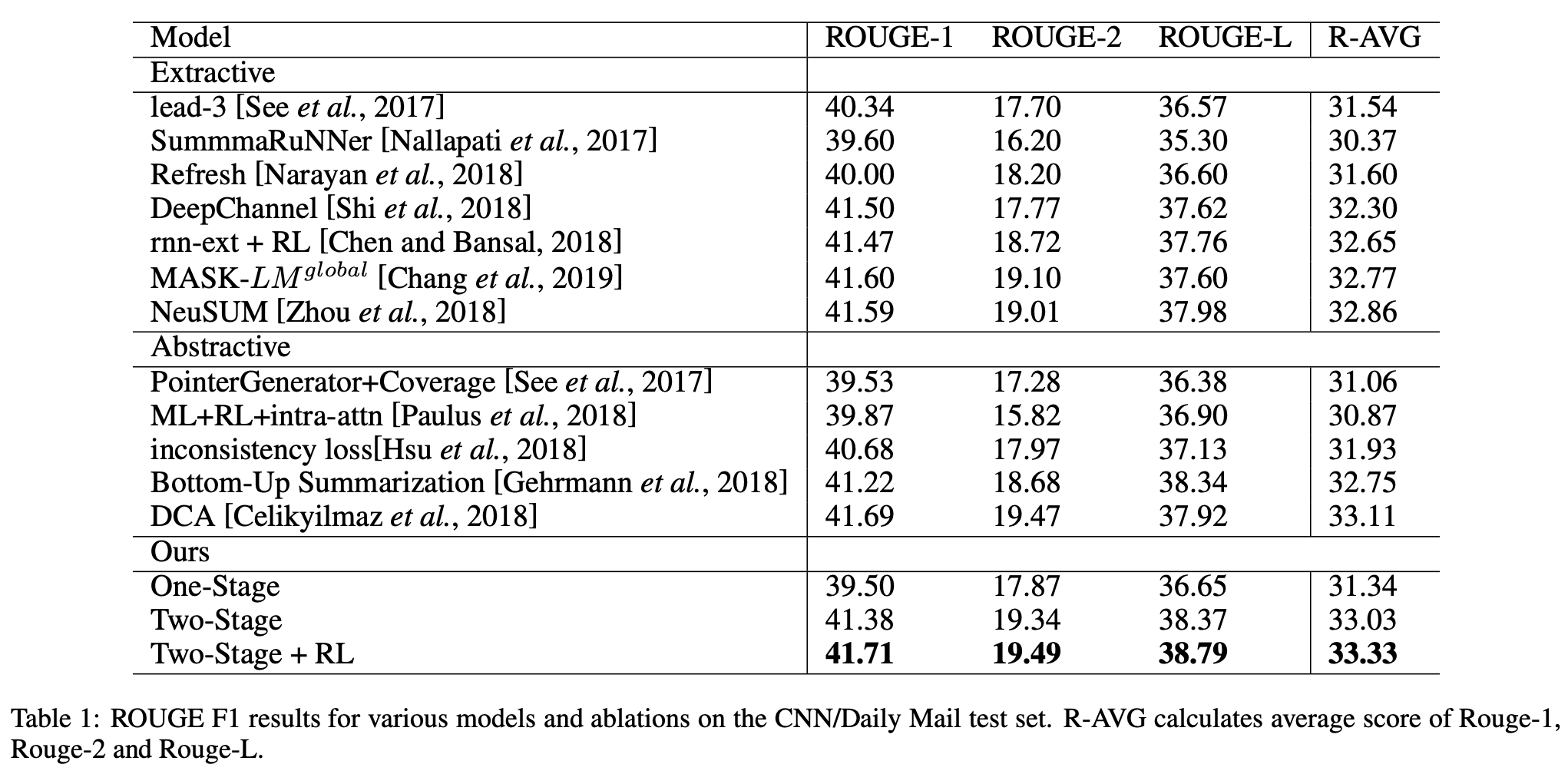
[Arxiv1904] Pretraining-Based Natural Language Generation for Text Summarization
- We encode the input sequence into context representations using BERT
- For the decoder, there are two stages in our model:
- use a Transformer-based decoder to generate a draft output sequence
- three steps:
- mask each word of the draft sequence and feed it to BERT
- combining the input sequence and the draft representation generated by BERT
- use a Transformer-based decoder to predict the refined word for each masked position
- The decoder cannot utilize BERT’s ability to generate high quality context vectors, which will also harm performance, but can use BERT’s contextualized representations to enhance the decoder in the refine process
- Introduce BERT’s word embedding matrix to map the previous summary draft outputs {y1, . . . , yt−1} into embeddings vectors {q1, . . . , qt−1} at t_th time step
- Incorporate copy mechanism [Gu et al., 2016] COPYNET based on the Transformer decoder
- BERT_LARGE needs unacceptable memory usage
- We filter repeated tri-grams in beam-search process by setting word probability to zero if it will generate an tri-gram which exists in the existing summary. It is a nice method to avoid phrase repetition since the two datasets seldom contains repeated tri-grams in one summary
Comments:
- Copy mechanism is same as Pointer-Generater but replace the RNN in seq2seq by transformer; not sure if this is the first work of doing so
- The imporvement on CNN and Daily Mail Dataset is not significant at all. It is not strict without a variance described
- The revise stage seems meaningless compared to the next work (see the BERT in result table);
- However, this work is a great trial of using deep language models (BERT) to generate text considering BERT is an auto-encoder based LM
- Here rasied a question: will ELMo, GPT-2, and XLNet better choices to generate text because of their auto-regressive property?
- A Chinese Blog
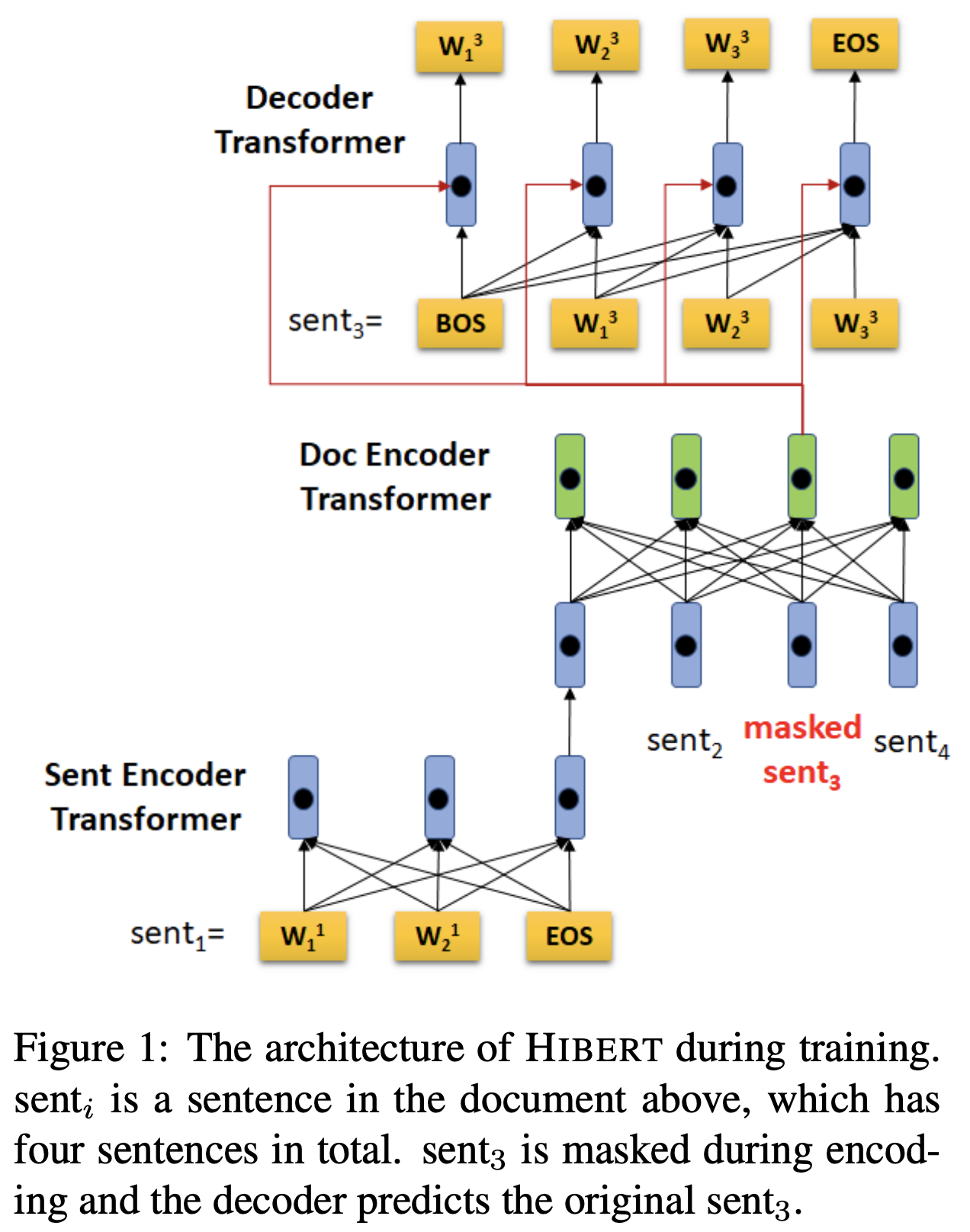
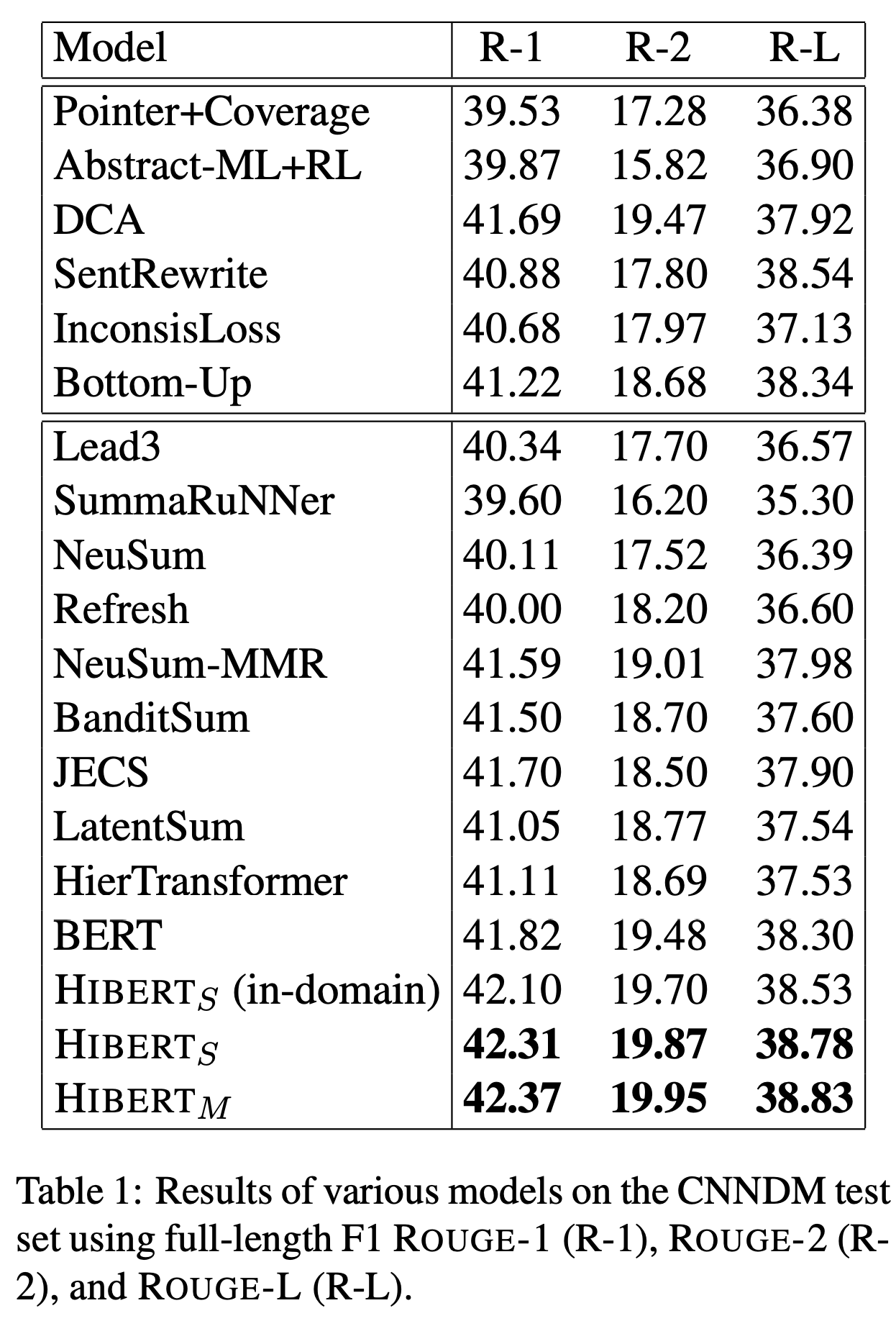
[ACL19] HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization
- Neural extractive summarization models usually employ a hierarchical encoder for document encoding and they are trained using sentence-level labels, which are created heuristically using rule-based methods and inaccurate
- Both the sentence encoder and document encoder are based on the Transformer encoder
- Document Masking: in summarization, context on both directions are available, so we opt to predict a sentence using all sentences on both its left and right
- Our model is trained in three stages, which includes two pre-training stages and one finetuning stage:
- open-domain pretraining and in this stage we train HIBERT on GIGA-CM dataset
- perform the indomain pre-training on the CNNDM (or NYT50)
- finetune HIBERT in the summarization model to predict extractive sentence labels
Comments:
- This work explores how to modify the architecture of BERT and pretrain it and finetune it
- Hirarchical BERT is good for document summarization and keyphrase generation, but will not benefit (visual) question answering task
- This work did not see the text generation loss for downstream task (summarization) and felt confused about how this model could generate text instead of tag of each sentence
[ICML19] MASS: Masked Sequence to Sequence Pre-training for Language Generation
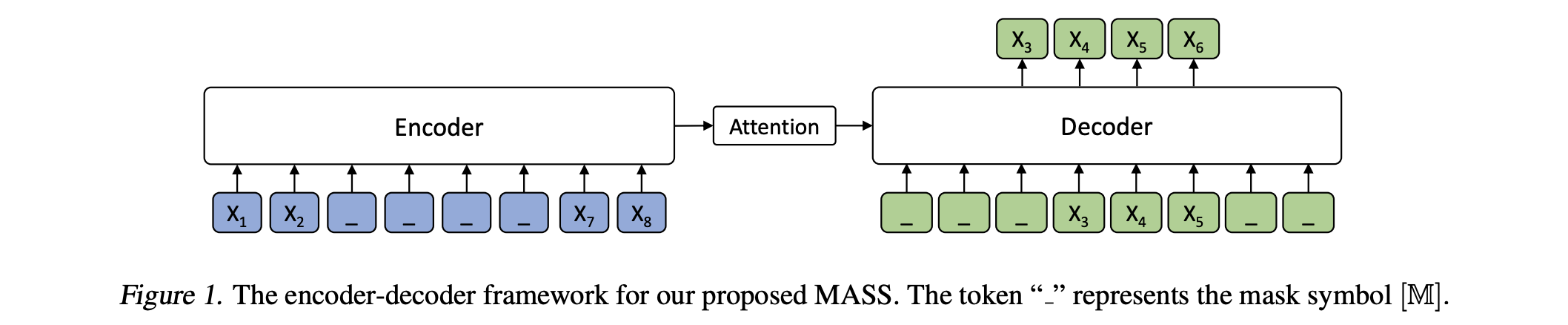

- MASS adopts the encoder-decoder framework to reconstruct a sentence fragment given the remaining part of the sentence:
- its encoder takes a sentence with randomly masked fragment (several consecutive tokens) as input
- its decoder tries to predict this masked fragment
- MASS is carefully designed to pre-train both the encoder and decoder jointly using only unlabeled data, and can be applied to most language generations tasks
- We have an important hyperparameter k, which denotes the length of the masked fragment of the sentence. Our method with different k values can cover the special cases that are related to previous pre-training methods
- While achieving promising results on language understanding tasks, BERT is not suitable for language generation tasks which typically leverage an encoder-decoder framework for conditional sequence generation
- By by predicting consecutive tokens in the decoder side, the decoder can build better language modeling capability than just predicting discrete tokens
- MASS achieves best performance on these downstream tasks when k is nearly 50% of the sentence length m
[EMNLP19] Text Summarization with Pretrained Encoders [code]
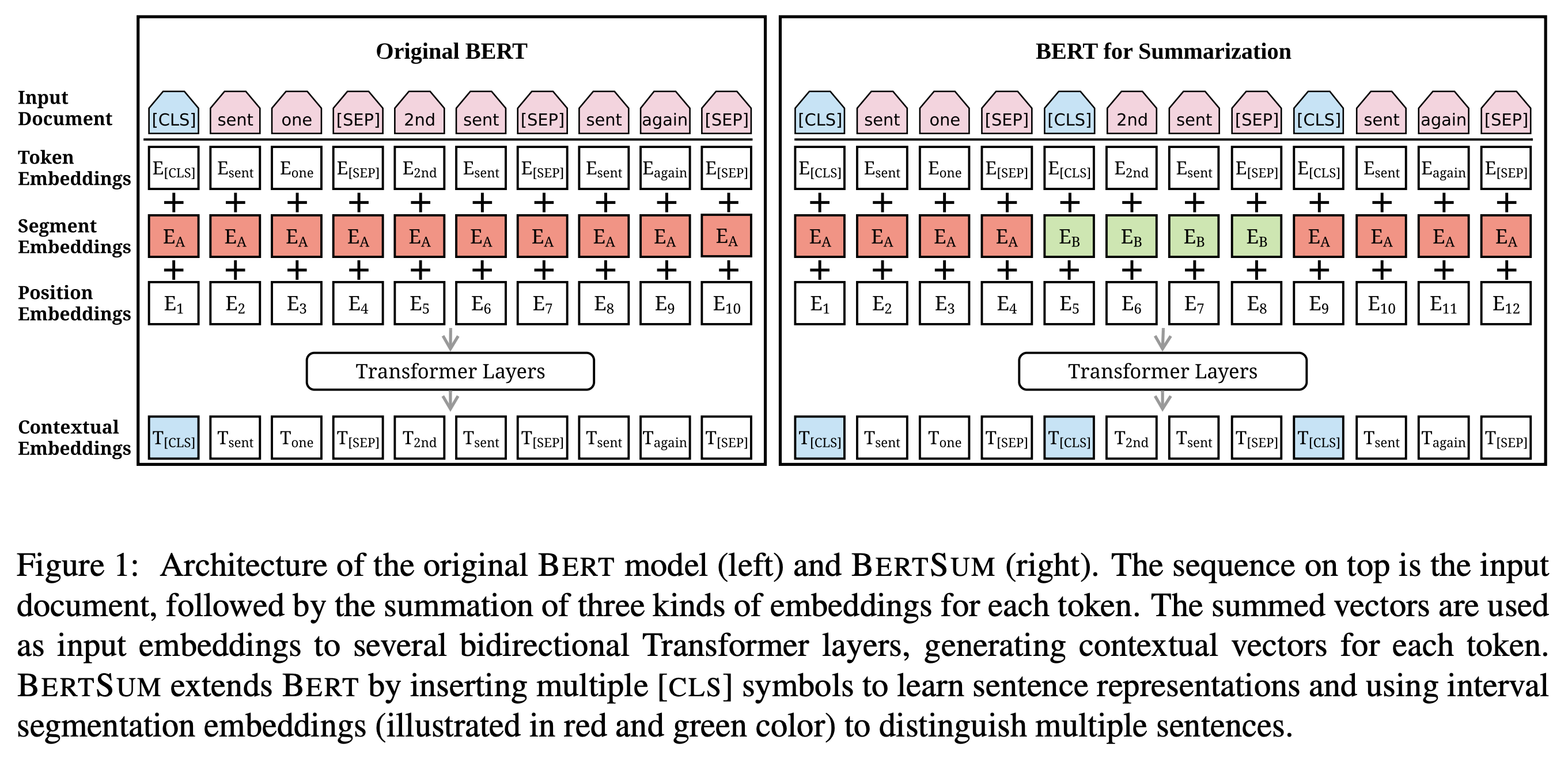
- We use a standard encoder-decoder framework for abstractive summarization (See et al., 2017). The encoder is the pretrained BERTSUM and the decoder is a 6-layered Transformer initialized randomly
- There is a mismatch between the encoder and the decoder, since the former is pretrained while the latter must be trained from scratch –> make fine-tuning unstable (the encoder might overfit the data while the decoder underfits) –> we design a new fine-tuning schedule which separates the optimizers of the encoder and the decoder
- Using extractive objectives can boost the performance of abstractive summarization
- Our decoder applies neither a copy nor a coverage mechanism (See et al., 2017), because we focus on building a minimum-requirements model and these mechanisms may introduce additional hyper-parameters to tune
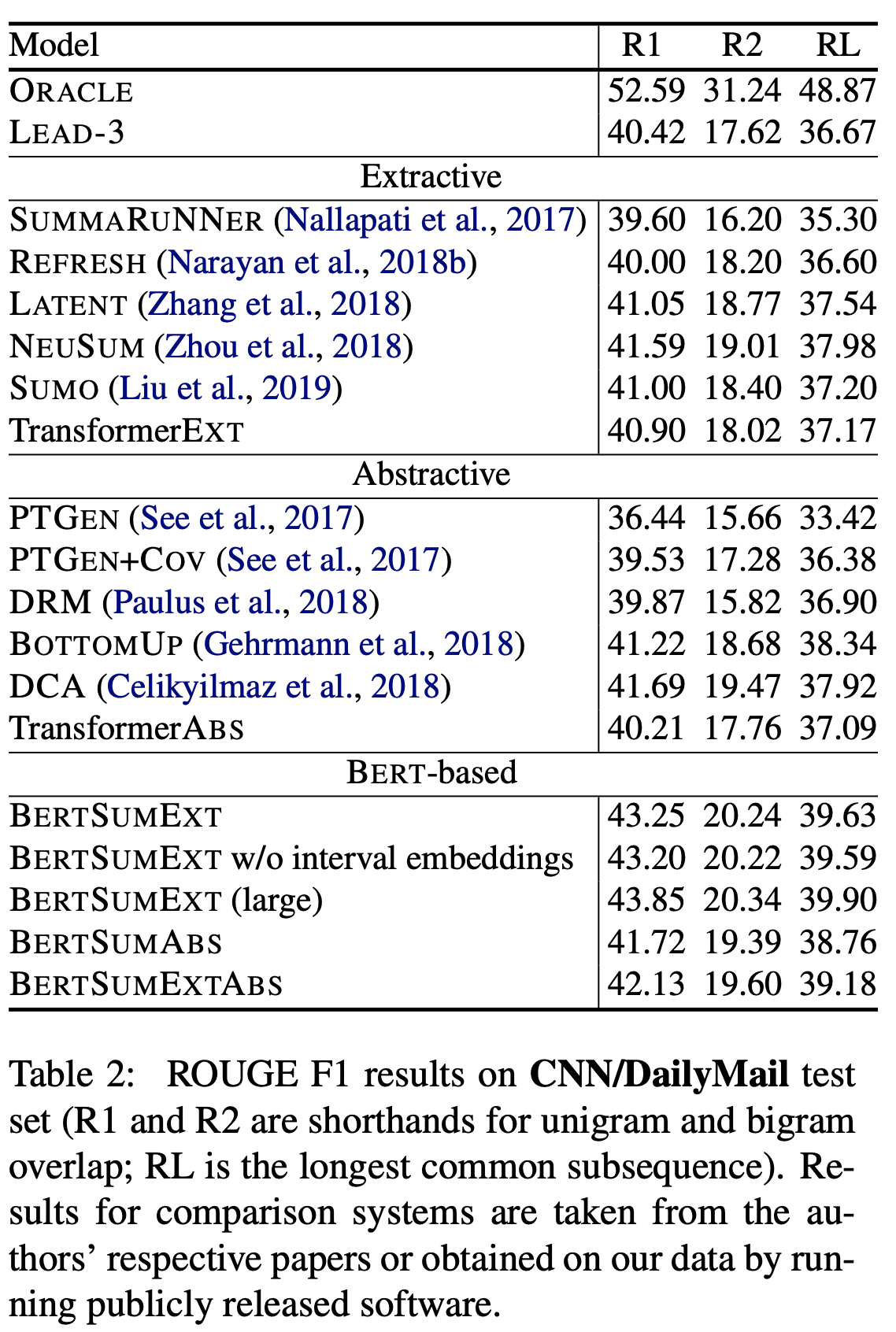
Comments:
- This work is indeed a minimum-requirements model with an original bert structure and adaptive data format
- The best results of CNN/DailyNews so far were mentioned
- The trick of separate optimizers is interesting but hyperparameter tuning metric is not solid
- The codes are written in pytorch, which is distributed and convenient to extend
[EMNLP19] Denoising based Sequence-to-Sequence Pre-training for Text Generation [code]
- Unlike encoder-only (e.g., BERT) or decoder-only (e.g., OpenAI GPT) pre-training approaches, PoDA jointly pretrains both the encoder and decoder by denoising the noise-corrupted text
- It keeps the network architecture unchanged in the subsequent fine-tuning stage
- We design a hybrid model of Transformer and pointer-generator networks as the backbone architecture for PoDA
- Like denoising autoencoders, PoDA works by denoising the noise-corrupted text sequences. There are three types of noises: randomly shuffle, delete or replace the words in a given sequence.
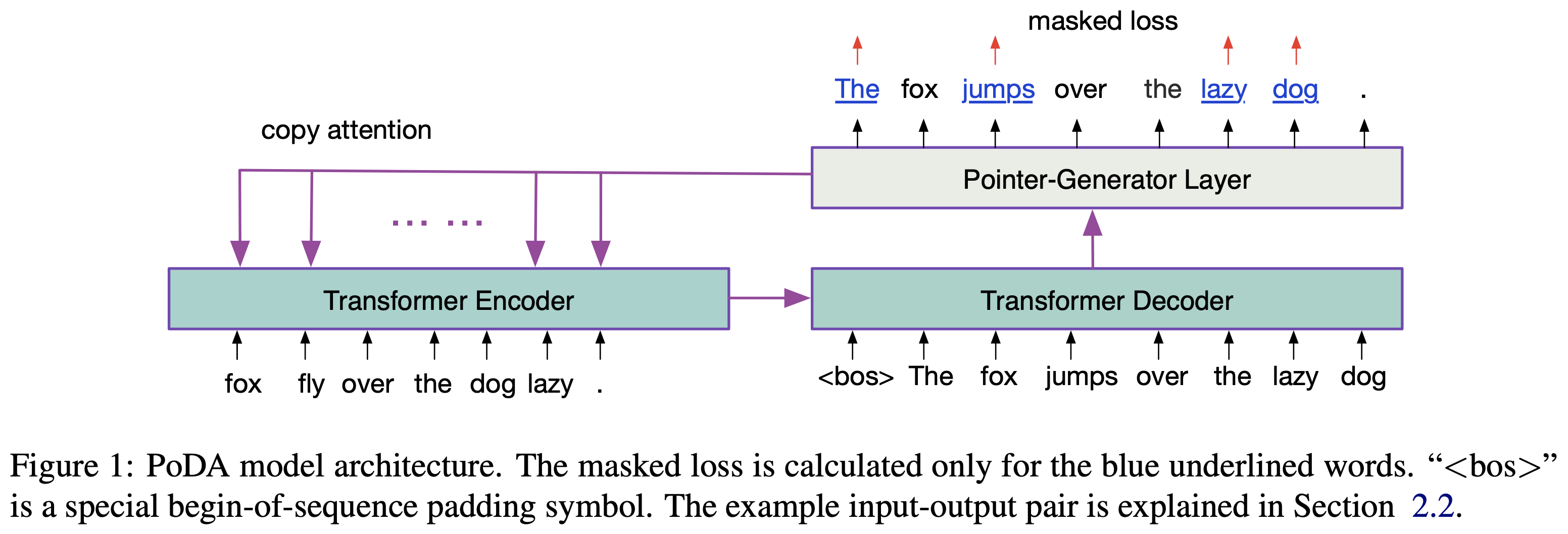
Comments:
- This work is interesting because it leveraged denosing autoencoder to pretrain the langage model
- Both BERT and GPT’s loss functions are used, which tackles the problem that BERT as an autoencoder language model, is not designed for text generation
- The analysis of linguistic quality is not solid with several sets of case study
- The difference between BERTSUM and PoDA:
- BERTSUM only pretrains encoder and uses different optimizers to tackle the mismatch between decoder and encoder but PoDA pretrains both encoder and decoder
- The training objective of BERTSUM is a document-version of BERT but PoDA uses autoencoder denosing method
- After comparing these two models, I prefer PoDA because it works as a whole and BERTSUM did a trivial improvement model-wise
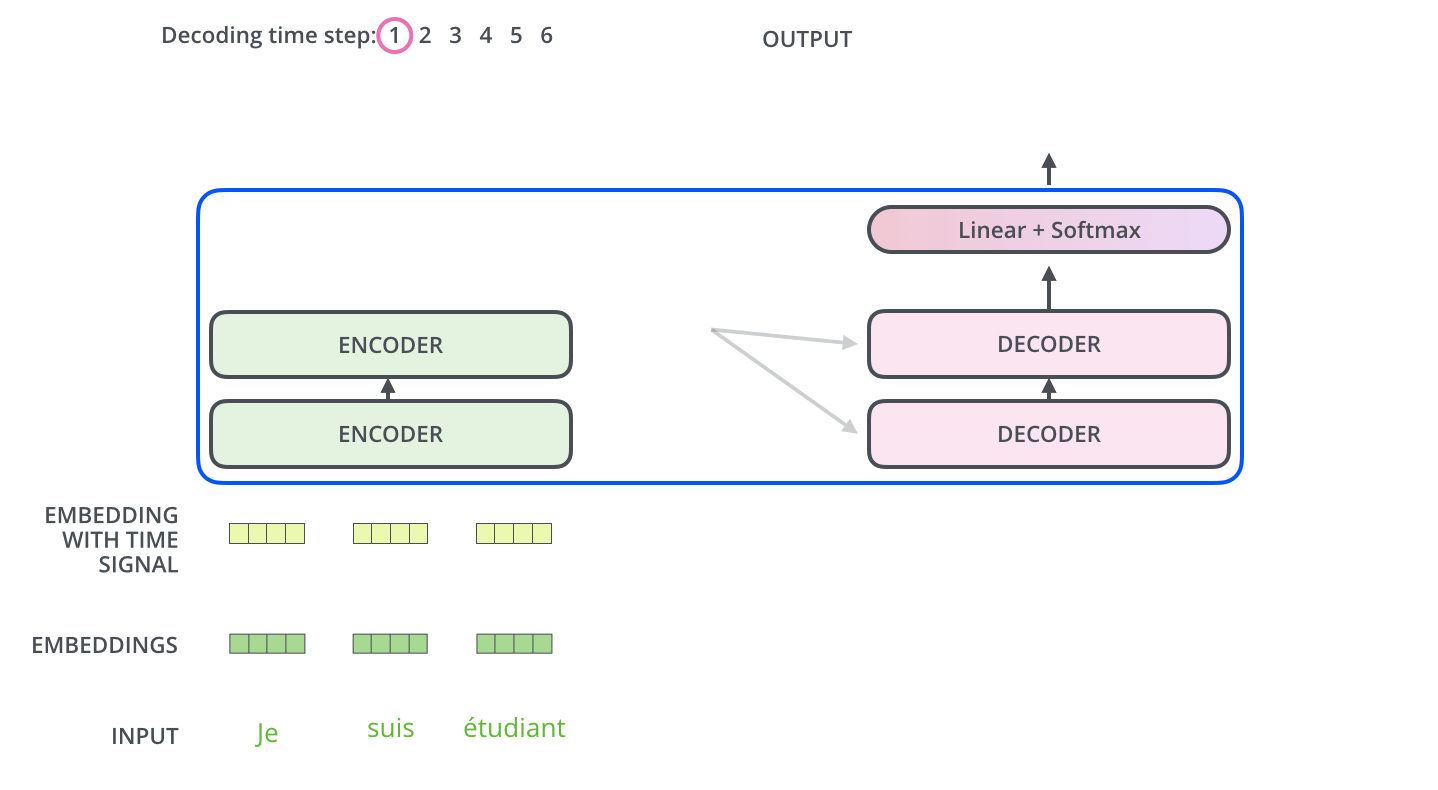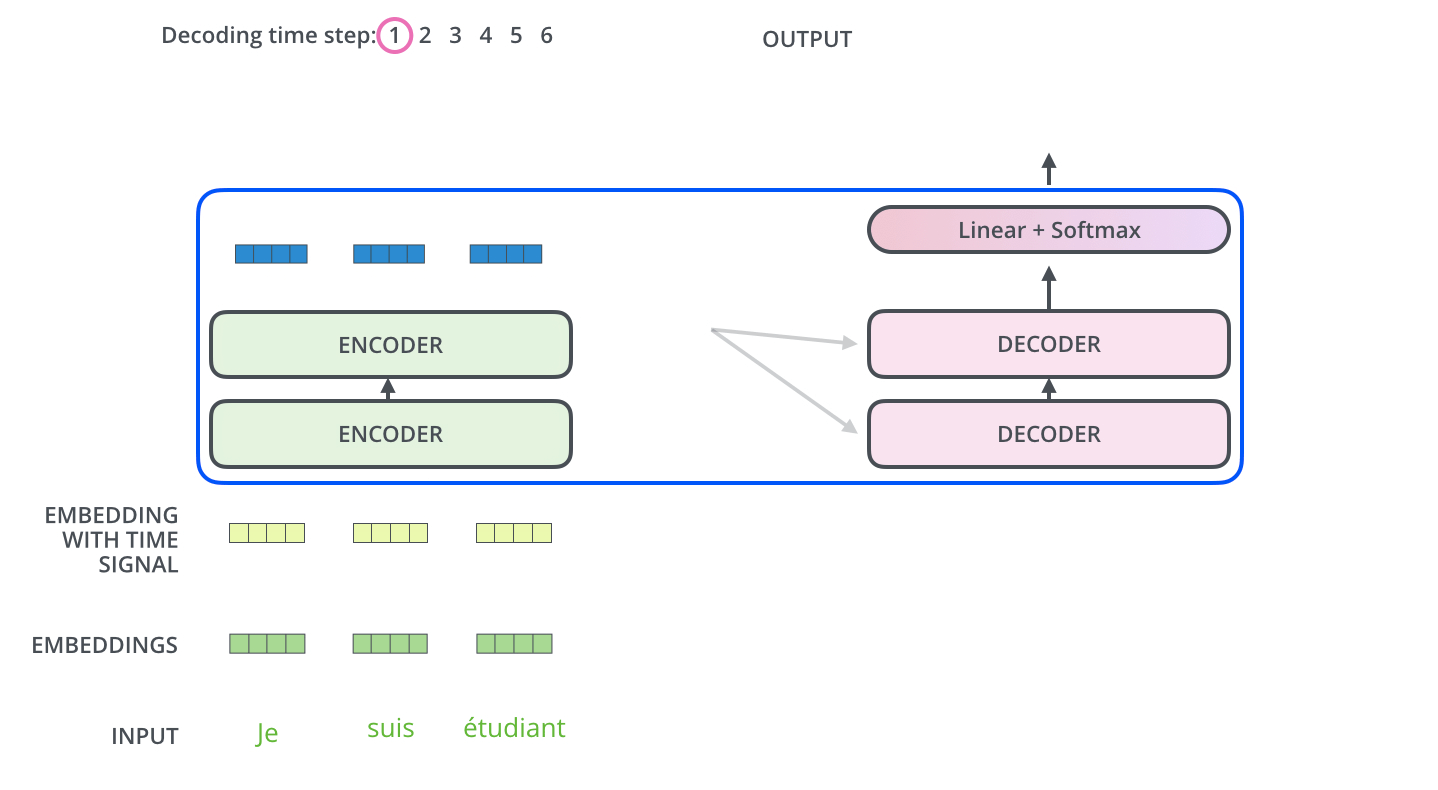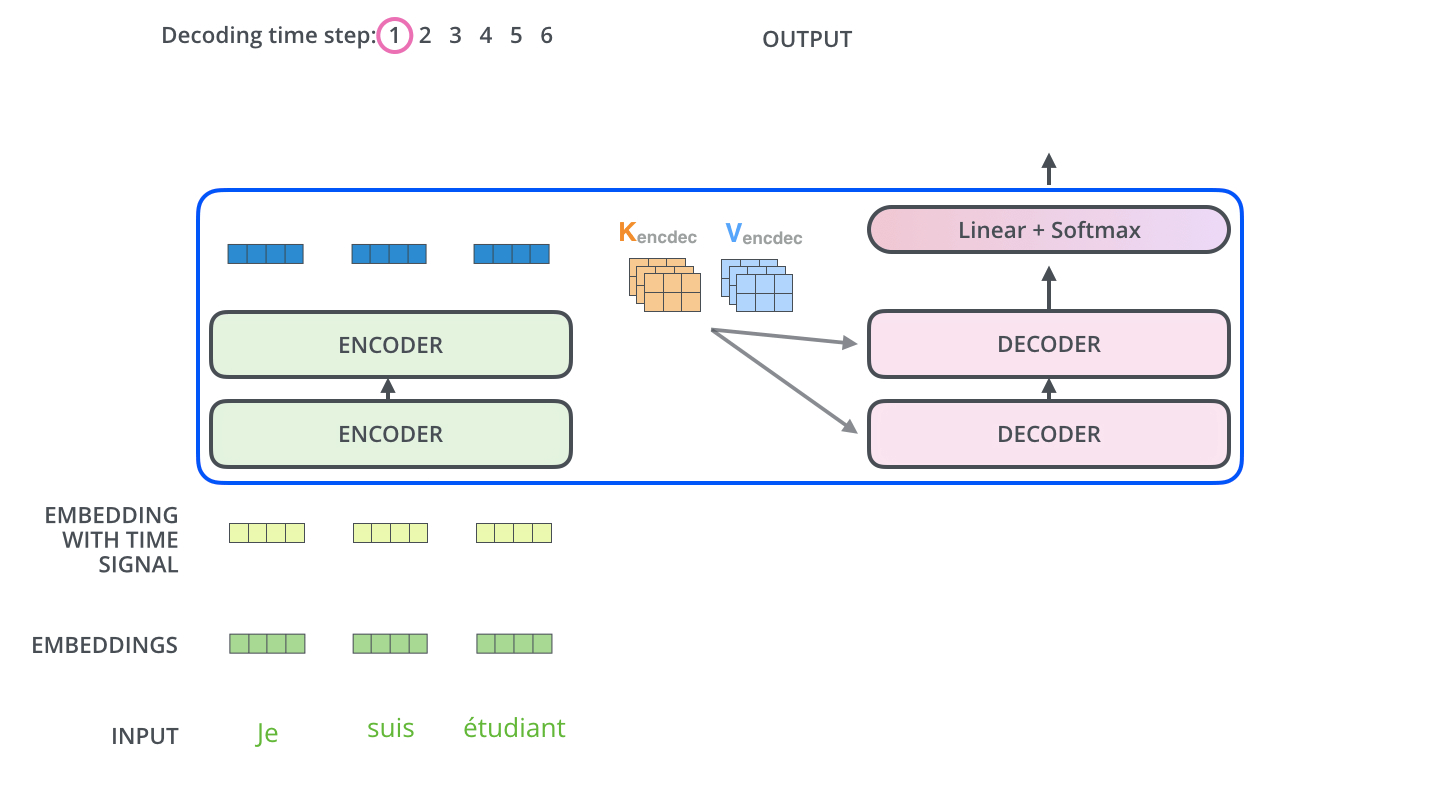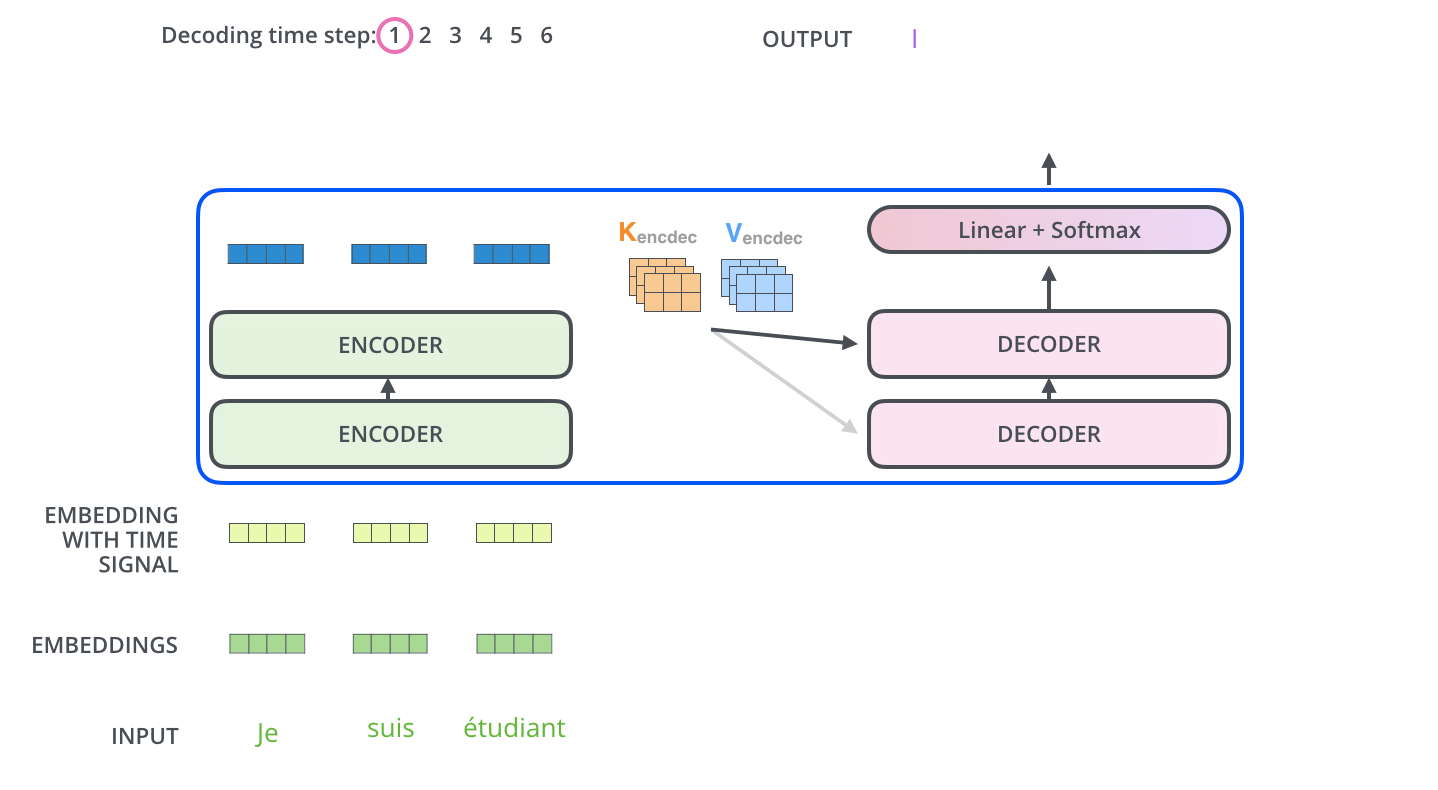
[NIPS17] Attention Is All You Need [tensorflow] [pytorch]
Comments:
- Here illustrated the mechanism of transformer decoder generating text: