Some Projects I've Involved in
My understanding of natural language processing is based on its various downstream applications. The ultimate goal is to mine the intention behind the language by analyzing the proximity, relationship and patterns among texts. I enjoy applying advanced NLP techniques to different domains, such as biomedicine, advertising and web data...
Low-resource Information Extraction
Cyber Security
- [Learning to Discriminate Perturbations for Blocking Adversarial Attacks in Text Classification]
Recently, adversarial attacks against machine learning models have been more and more prevailing and threatened various real-world applications such as email spam filters and sentiment analysis. In this paper, we propose a novel framework, learning to DIScriminate Perturbations (DISP), to discriminate and adjust malicious perturbations, thereby blocking adversarial attacks for text classification models. To identify adversarial attacks, a perturbation discriminator validates the likelihood to be perturbed for each token in the text and provides a set of potential perturbations. For each potential perturbation, an embedding estimator exploits context tokens to approximate the actual embeddings. Hierarchical navigable small world graphs are then applied to efficiently convert the embeddings to appropriate replacement tokens for approximate k NN search.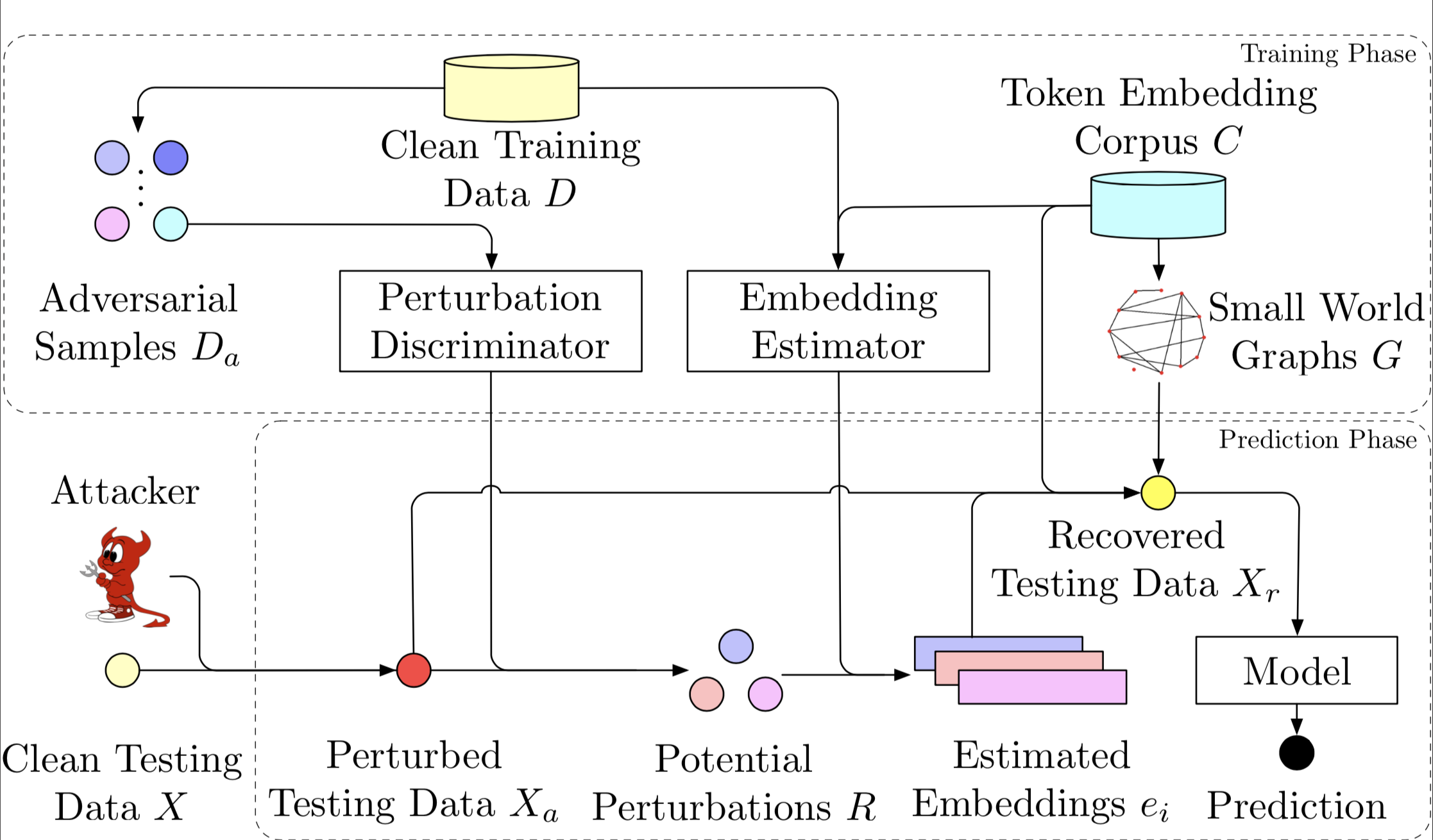
Implicit Language Bias
- [Gender-neutral word embeddings]
Word embedding models have become a fundamental component in a wide range of Natural Language Processing (NLP) applications. However, embeddings trained on human-generated corpora have been demonstrated to inherit strong gender stereotypes that reflect social constructs. To address this concern, in this project, we propose a novel training procedure for learning gender-neutral word embeddings. Our approach aims to preserve gender information in certain dimensions of word vectors while compelling other dimensions to be free of gender influence. Based on the proposed method, we generate a Gender-Neutral variant of GloVe (GN-GloVe). Quantitative and qualitative experiments demonstrate that GN-GloVe successfully isolates gender information without sacrificing the functionality of the embedding model.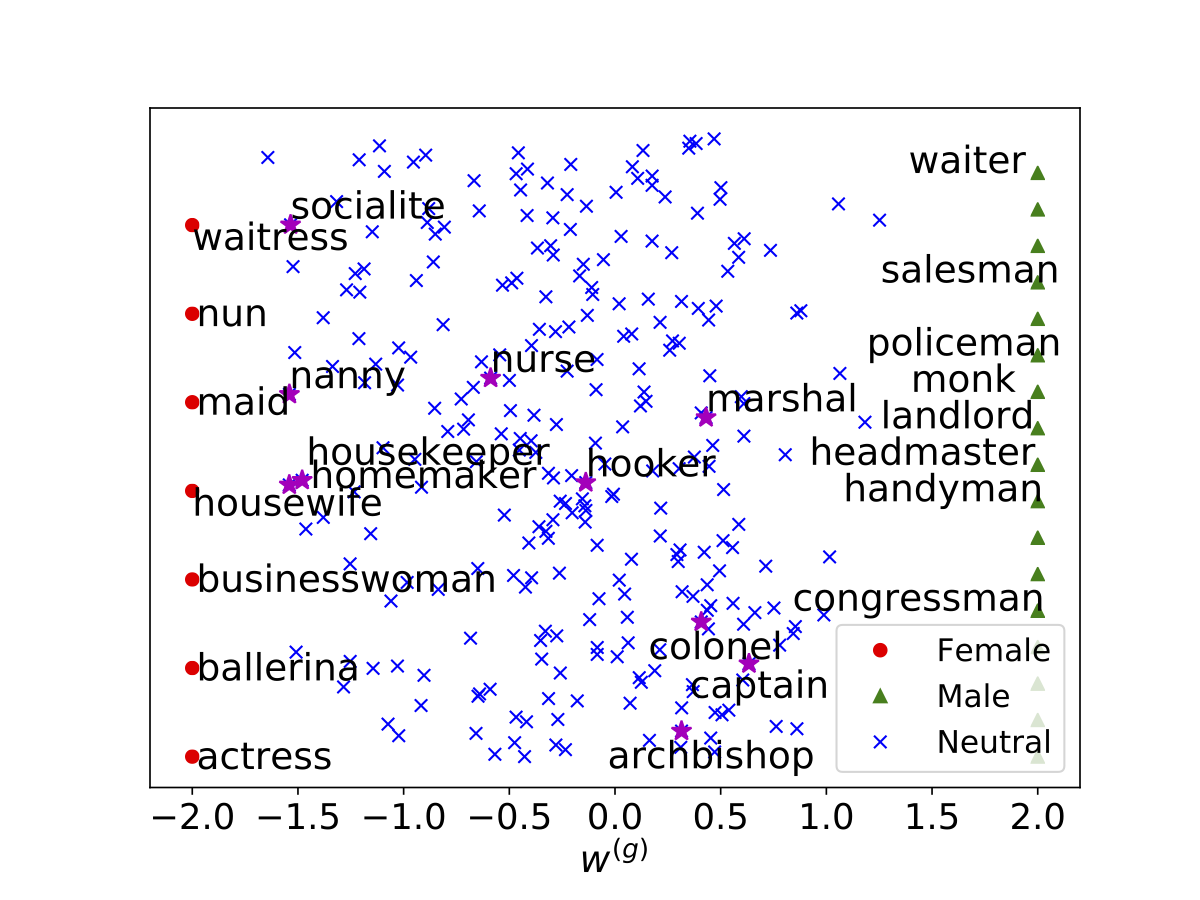
Multi-lingual Relation Extraction
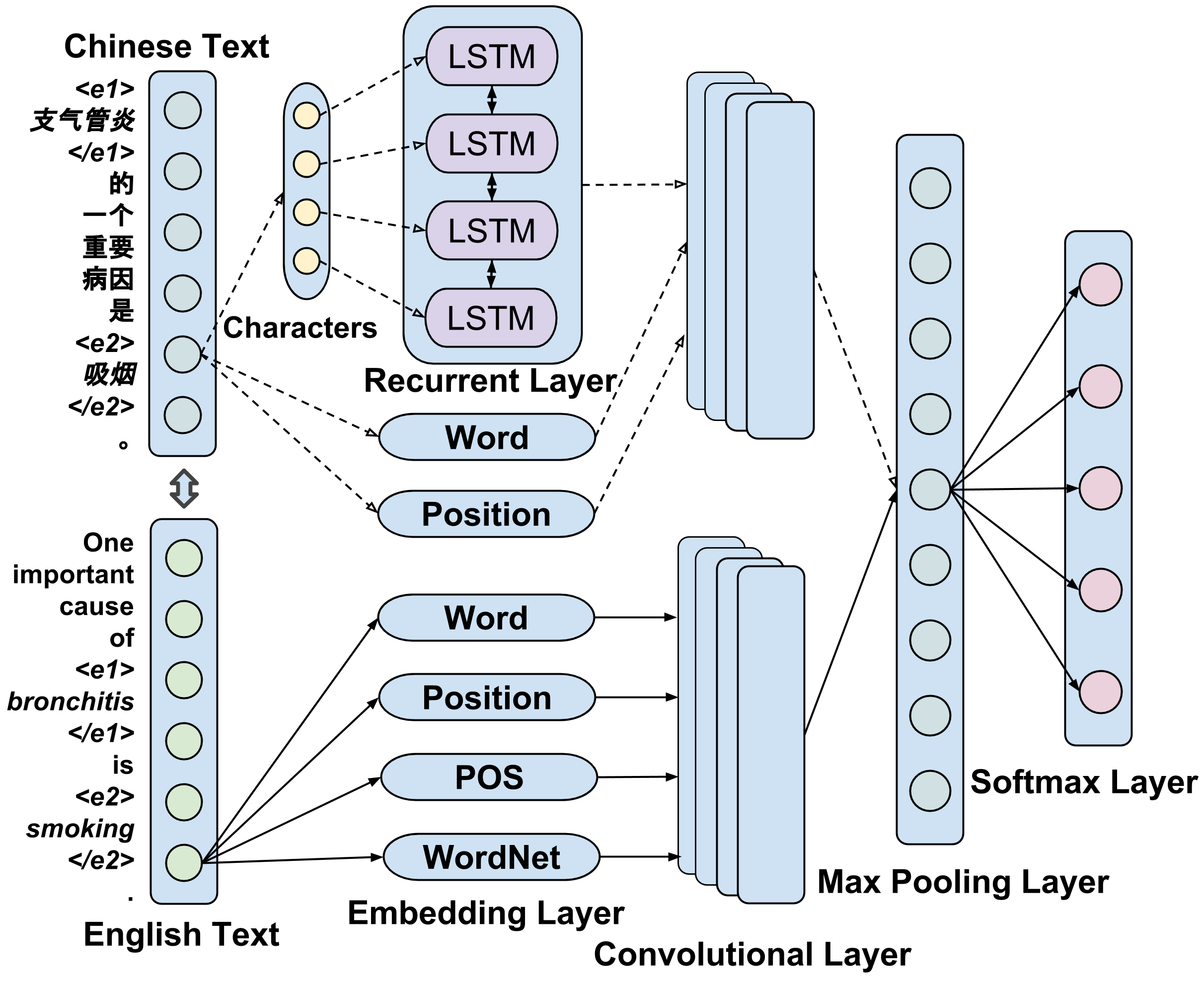
- [Bilingual relation classification]
Relation classification is an important semantic processing task in natural language processing field. Nowadays, a large amount of knowledge in different languages exists but is rarely leveraged for relation classification tasks. Besides, most current approaches for relation classification only exploit word-level features. However, character-level features are also worth investigating, especially for languages that have rich character-level semantics, such as Chinese. In this project, we propose a novel deep neural network based model, omni-RCNN, which leverages the omni-word features extracted from bilingual datasets.
Advertising
- Understanding consumer journey using attention-based RNN
Paths of online users towards a purchase event (conversion) can be very complex, and guiding them through their journey is an integral part of online advertising. Studies in marketing indicate that a conversion event is typically preceded by one or more purchase funnel stages, viz., unaware, aware, interest, consideration, and intent. Intuitively, some online activities, including web searches, site visits and ad interactions, can serve as markers for the user’s funnel stage. Identifying such markers can potentially refine conversion prediction, guide the design of ad creatives (text and images), and lead to higher ad effectiveness. We explore this hypothesis through a set of experiments designed for two tasks: (i) conversion prediction given a user’s activity trail, and (ii) funnel stage specific targeting and creatives. To address challenges in the two tasks, we propose an attention based recurrent neural network (RNN) which ingests a user activity trail, and predicts the user’s conversion probability along with attention weights for each activity (analogous to its position in the funnel). Specifically, we propose novel attention mechanisms, which maintain a global weight for each activity across all user trails, and also indicate the activity’s funnel stage. Use of the proposed attention mechanisms for the first task of conversion prediction shows significant AUC lifts of 0.9% on a public dataset (RecSys 2015 challenge), and up to 3.6% on three proprietary datasets from a major advertising platform (Yahoo Gemini). To address the second task, the activity weights from the proposed mechanisms are used to automatically assign users to funnel stages via a scalable scoring method. Offline evaluation shows that such activity weights are more aligned with editorially tagged activity-funnel stages compared to weights from existing attention mechanisms and simpler conversion models like logistic regression. In addition, results of online ad campaigns in Yahoo Gemini with funnel specific user targeting and ad creatives show strong performance lifts further validating the connection across online activities, purchase funnel stages, stage-specific custom creatives, and conversions.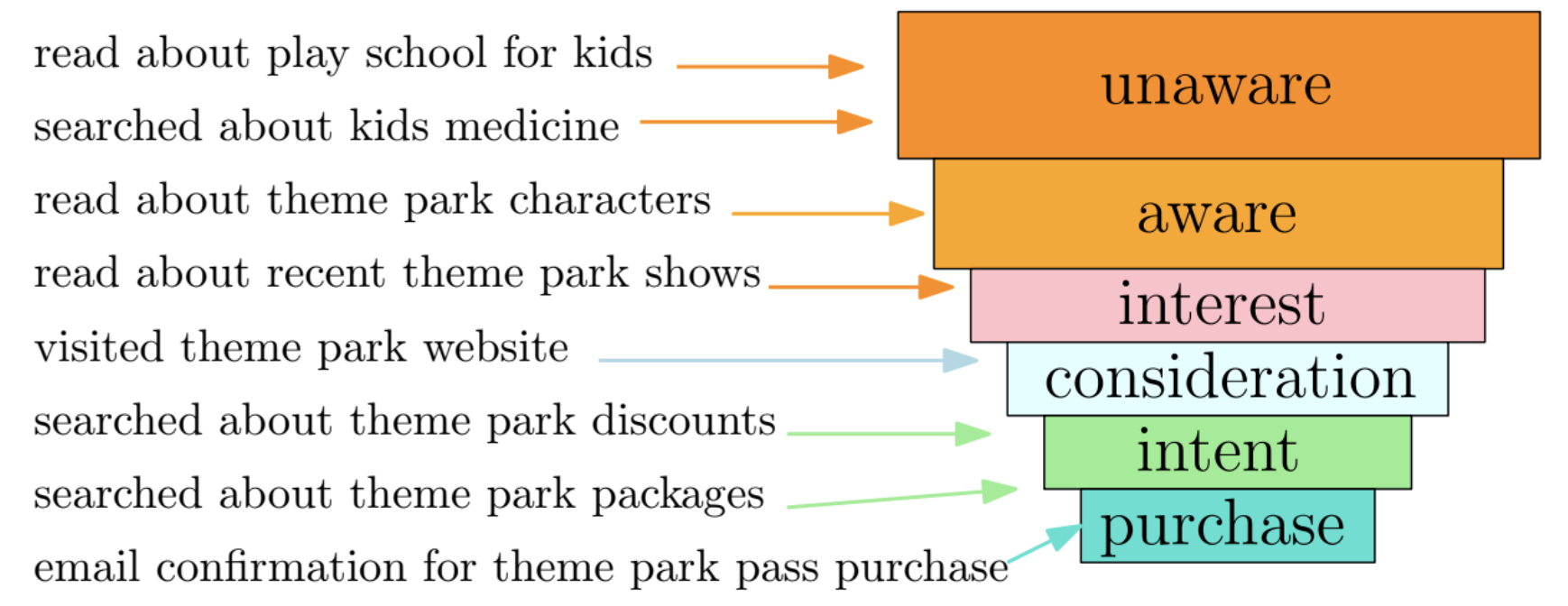
Biomedical Document Curation
-
AZTec
BD2K Aztec is a global biomedical resource discovery index that allows users to simultaneously search a diverse array of tools. The resources indexed include web services, standalone software, publications, and large libraries composed of many interrelated functions. Aztec will ensure that software tools remain findable in the long term by issuing persistent DOIs and routinely updating metadata for the entire index. Aztec’s established ontologies and robust API support the programmatic query of its entire database, as well as the construction of indexes for specialized subdomains. Aztec fosters an environment of sustainable resource support and discovery, empowering researchers to overcome the challenges of information science in the 21st century.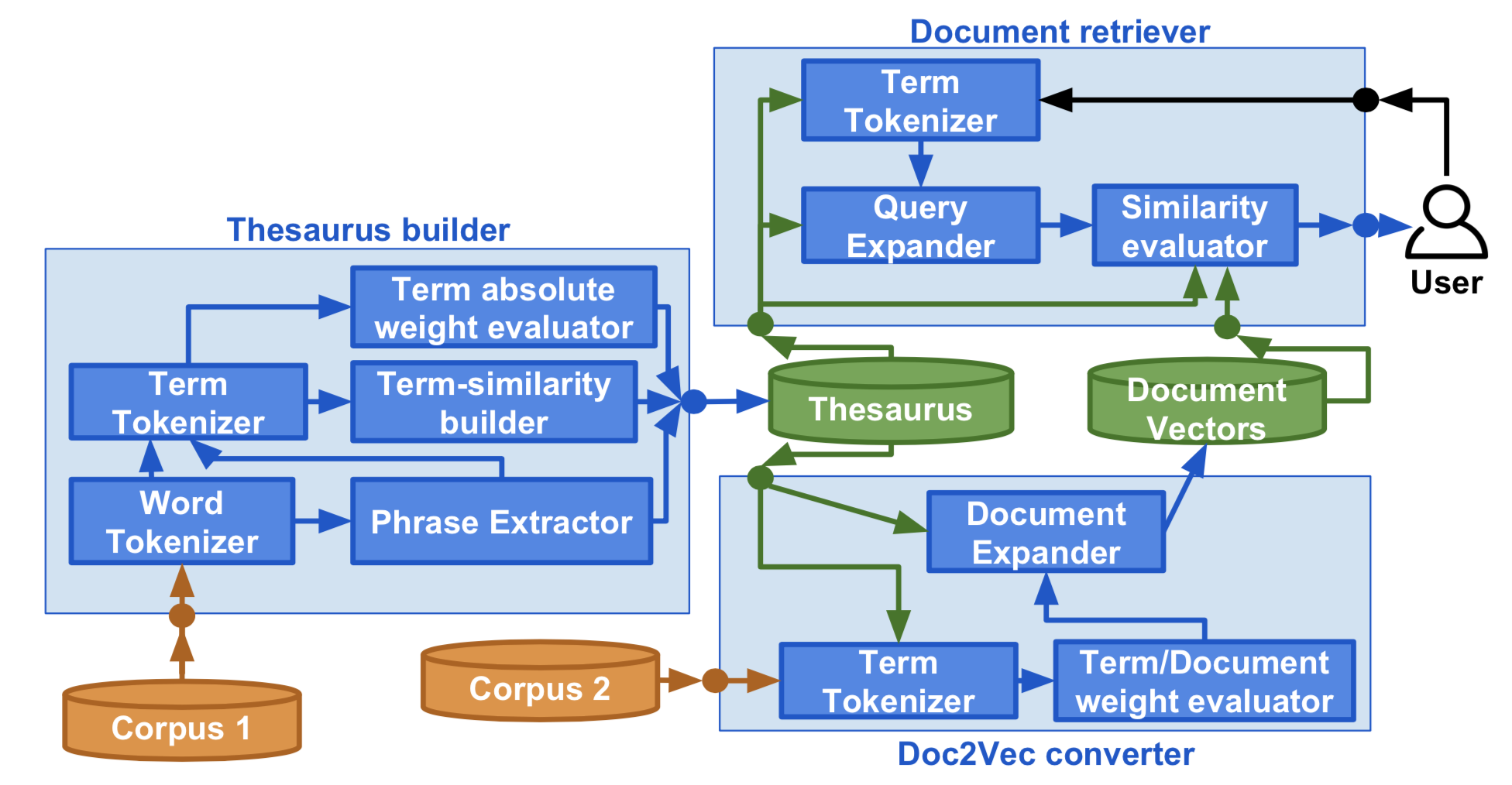
-
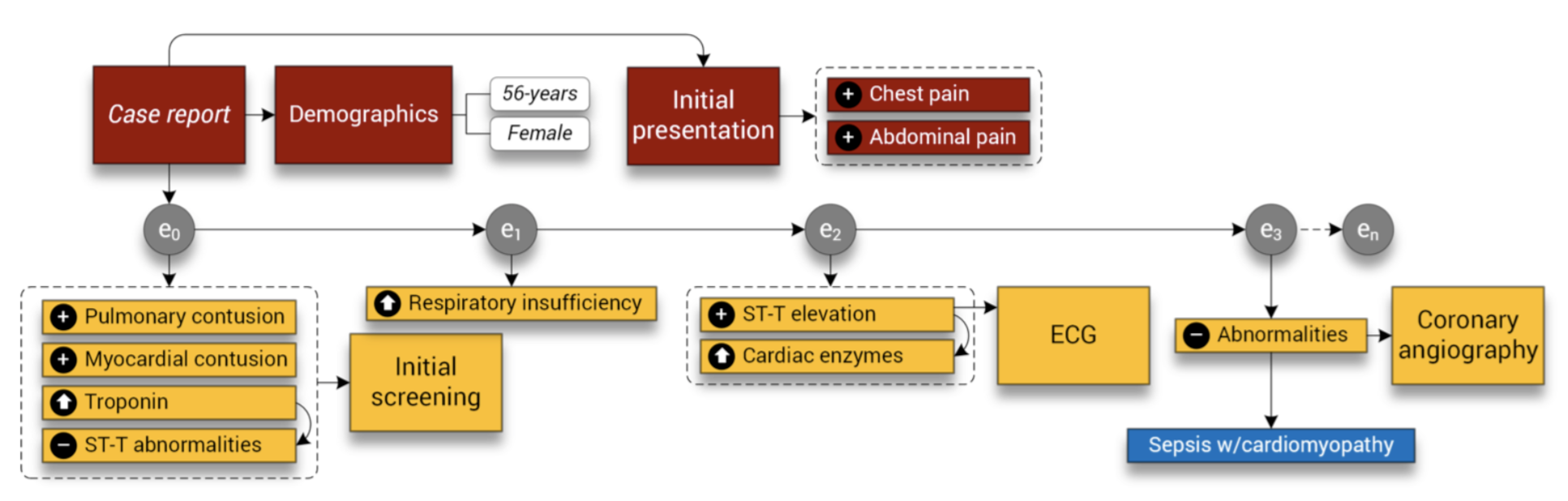
[CREATe]
[Paper] Clinical case reports have been a longstanding type of communication within the medical literature, seeking to document interesting patient cases. The narrative of a case report details the signs/symptoms, diagnosis, treatment, and outcome of an individual, describing observations made over the course of clinical care. Often these case reports contain exceptionally valuable clinical data, addressing unusual disease situations. As such, they are an important biomedical research data source for uncovering novelty (e.g., new diseases, unusual presentation of common diseases, rare diseases) and detecting adverse events. This project develops algorithms for extracting, indexing, and querying the contents of clinical case reports. Our proposed system, CREATe, automates generation of metadata about case reports, inlcuding named entity recognition and temporal relation extraction, unlocking this important big data resource through a searchable portal.