
It’s that time of the year when a major data conference conference opens and releases the papers to the public, so it’s time to check what are the hot topics this year.
I extracted the keywords from the abstracts of all accepted papers in KDD 19 with their frequencies.
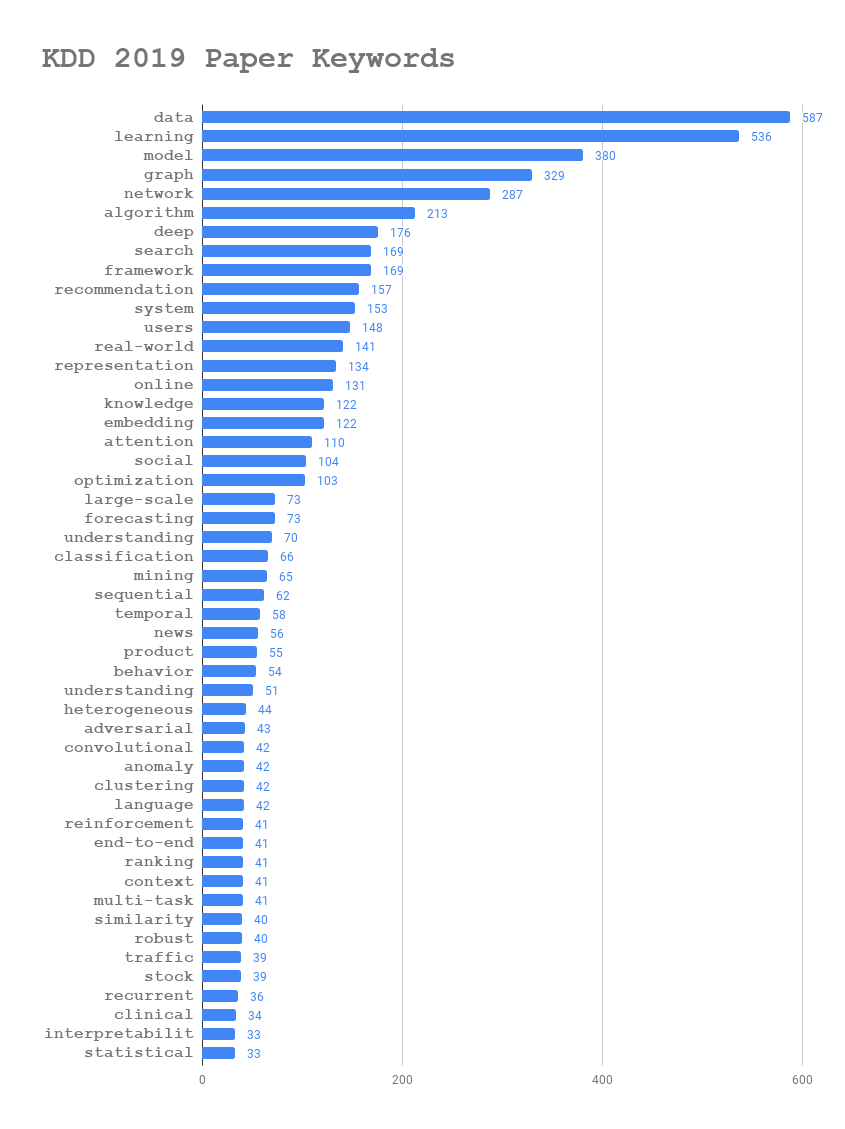
Some insights:
- Graph and Network Embedding are dominant in KDD; the networks are mostly heterogeneous network; knowledge graph track is growing
- Deep models have been necessary for machine learning tasks
- Search, recommendation, ranking are still the core of KDD
- KDD cares more about real-world problems (similar to WWW?) and online learning is one application
- Some hot topic: temporal data processing, anomaly data understanding, reinforcement learning, adversarial learning, multi-task learning (what’s the difference from ICML?)
- Natural language processing tools are prevailing such as embedding methods and deep language models
- The models are better to be large-scale, end-to-end and interpretable; framework or system might be preferable than an individual model
- Some hot domains: news, advertising, traffic, stock and social network
- Some basic deep models to use: convolutional and recurrent networks, attention mechanisms
There was also a story during kdd that I want to share. I met Prof. Cho-jui Hsieh, one of my phd committee, during one poster session on Aug. 6 and I started a conversation with him. Considering that I was working on keyphrase generation from visual ads images, I told him my ideas and questions. “Choi, you know, deep language models have been prevailing in the nlp communities and even the kdd people like to build IR models on top of them. Beside, we also have a bunch of pre-trained image models like vggnet and resnet. Why don’t we build a joint pretrianed model to learn a relation between image and text?” Choi looked at me and smiled, “Kai-Wei and I have been working on a similar problem as you mentioned. You can ask him if you are interested in that.” I was a little suprised but it did make sense that such a hot topic should have been researched somewhere in the world.
Something I did not expect was that on the exact same day, a work called VilBERT was released on Arvix. They reseached on a image-language joint pretraining objective and had a great success. Three days after, Kai-Wei and Choi’s work VisualBERT was also released. Now I felt astonished because they finished the study so quickly but I just come up with this immature idea.
Something I can conclude from this short story is that continuously reading new papers, attending top-tier conferences and actively talking with professors are the necessary ways to avoid latency of research.
Updates:
The visual-Language joint modeling problem is really hot and related researchers kept releaseing papers. Here is a good one (VL-BERT) with summary of previous work. I put the link here for future reference.