
[CVPR 2018] Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
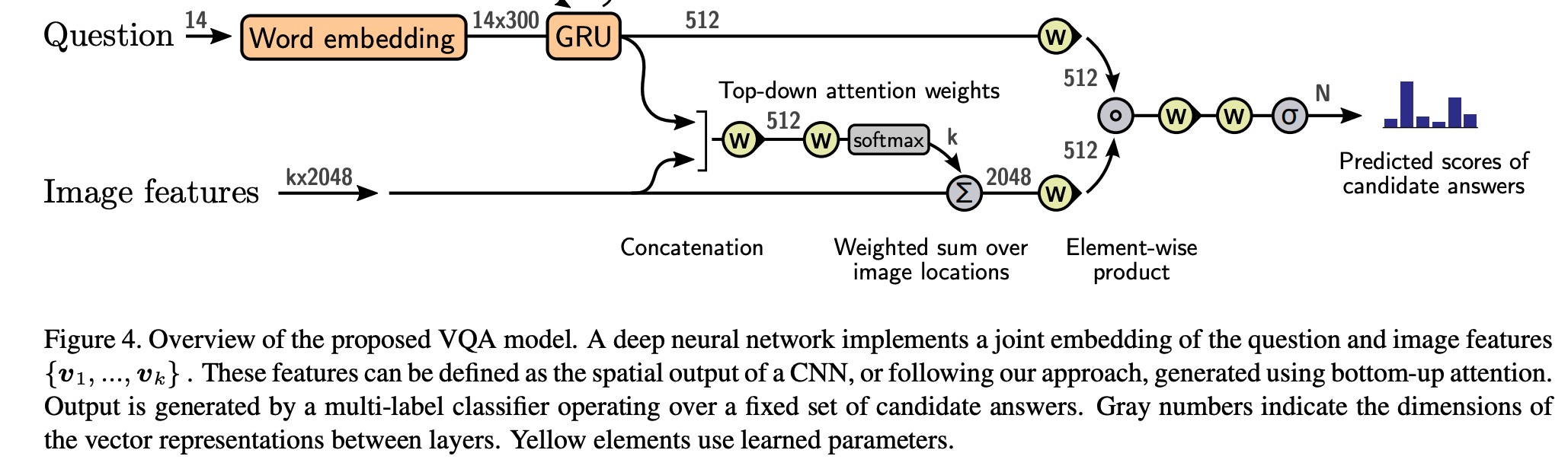
- image processing: the bottom-up mechanism (based on Faster R-CNN) proposes image regions, each with an associated feature vector, while the top-down mechanism determines feature weightings
- use Faster R-CNN (an object detection model designed to identify instances of objects belonging to certain classes and localize them with bounding boxes) in conjunction with the ResNet-101 CNN
- captioning model uses a ‘soft’ top-down attention mechanism to weight each feature during caption generation, using the existing partial output sequence as context
- results on the MSCOCO test server establish a new state-of-the-art for the task, achieving CIDEr / SPICE / BLEU-4 scores of 117.9, 21.5 and 36.9

[ECCV 2018] ADVISE: Symbolism and External Knowledge for Decoding Advertisements
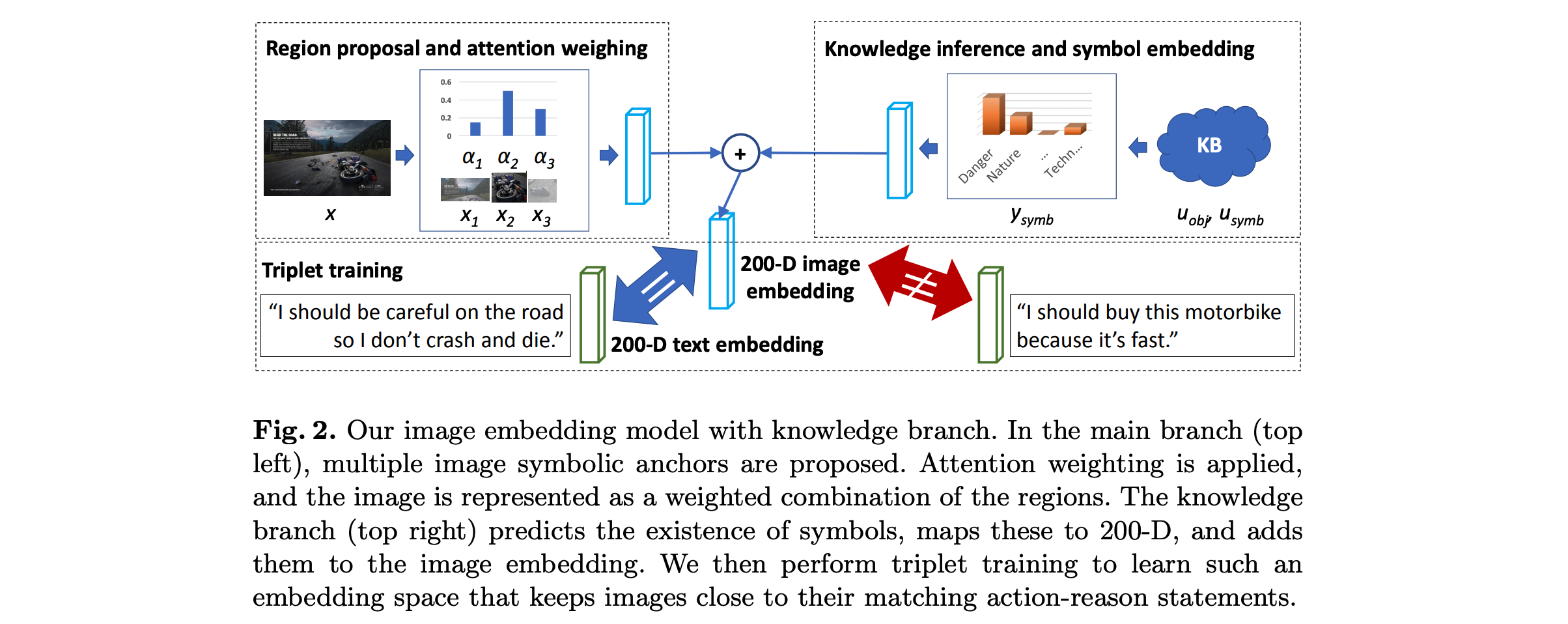
- question answering is formulated as a classification task: For each image, we use three related statements (i.e. statements provided by humans for this image) and randomly sample 47 unrelated statements
- the distance between an image and its corresponding statement should be smaller than the distance between that image and any other statement
- extract the image’s Inception-v4 CNN feature (1536-D), then use a fully-connected layer with parameter w ∈ R^(200×1536) to project it to the 200-D joint embedding space
- use mean-pooling (a. comparable performance to the LSTM; b. better interpretability) to aggregate word embedding vectors into 200-D text embedding t and use GloVe to initialize the embedding matrix
- use the SSD object detection model, pretrain it on the COCO dataset, and fine-tune it with the symbol bounding box annotations
- use bottom-up attention(previous paper) to aggregate the information from symbolic regions –> intuition is that ads draw the viewer’s attention in a particular way, and the symbol bounding boxes, without symbol labels, can be used to approximate this
- use the DenseCap model to generate image captions and treat these as pre-fetched knowledge
- use a predicted symbol distribution at both training and test time as a secondary image representation
- use a train/val/test split of 60%/20%/20%, resulting in around 39,000 images and more than 111,000 associated statements for training
- compute two metrics: Rank and Recall@3
Drawbacks:
- big ratio of visual ads are straightforward and do not contain symbolic features or rehtoric designs. In these cases, constraints via symbols could not be applied
- the weights for symbol-based and object-based constraints are manually set as 0.1
- external symbolic knowledge base is shallow: the symbol size is limited; only 5 related words are related to each symbol instead of a word distribution
- compared with generation, classification task has a finite searching space, which is much simpler
[AAAI19] KVQA: Knowledge-aware Visual Question Answering
- In conventional VQA, one may ask questions about an image which can be answered purely based on its content; More recently, there is growing interest in answering questions which require commonsense knowledge involving common nouns (e.g., cats, dogs, microphones); the important problem of answering questions requiring world knowledge about named entities.
- KVQA con- sists of 183K question-answer pairs involving more than 18K named entities and 24K images. Questions in this dataset require multi-entity, multi-relation, and multi-hop reasoning over large Knowledge Graphs (KG) to arrive at an answer.
- Obviously, the knowledge graph can be Wikidata (Vrandecic and Kro ̈tzsch 2014).
- We used the latest RDF dump (dated: 05-05-2018) of this KG. It stores facts in the form of triples, i.e., subject, relation and object.
- Project website containing the dataset and codes
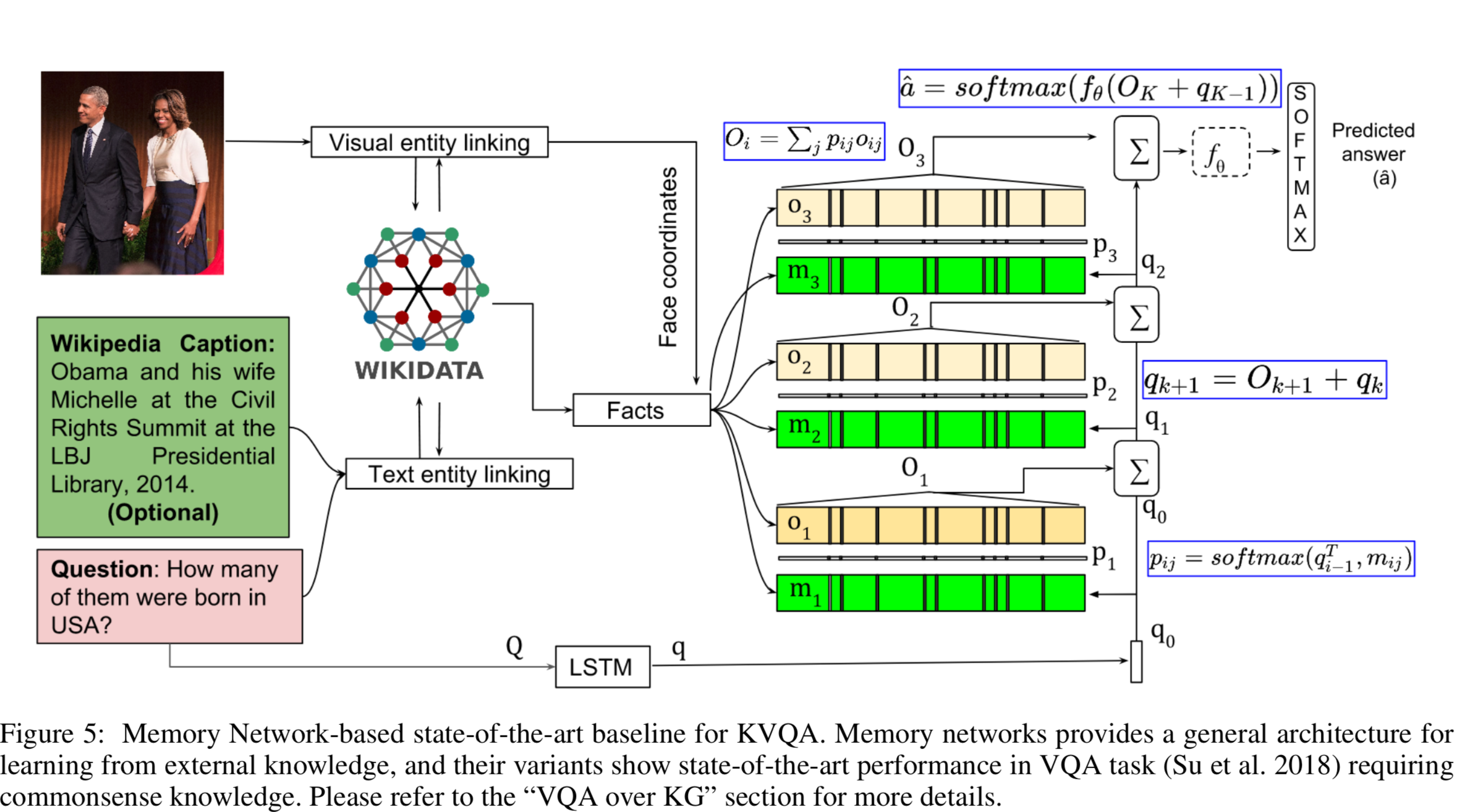
- We choose memory network (memNet) (Weston, Chopra, and Bordes 2014) as one of our baselines for KVQA. Memory network provides a general architecture for learning from external knowledge.
- Each knowledge and spatial fact is fed to BLSTM to get corresponding memory embeddings mi. Question embeddings (q) for a question (Q) is also obtained in a similar fashion.
[CVPR 2019] OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge
- In this paper, we address the task of knowledge-based visual question answering and provide a benchmark, called OK-VQA, where the image content is not sufficient to answer the questions, encouraging methods that rely on external knowledge resources.
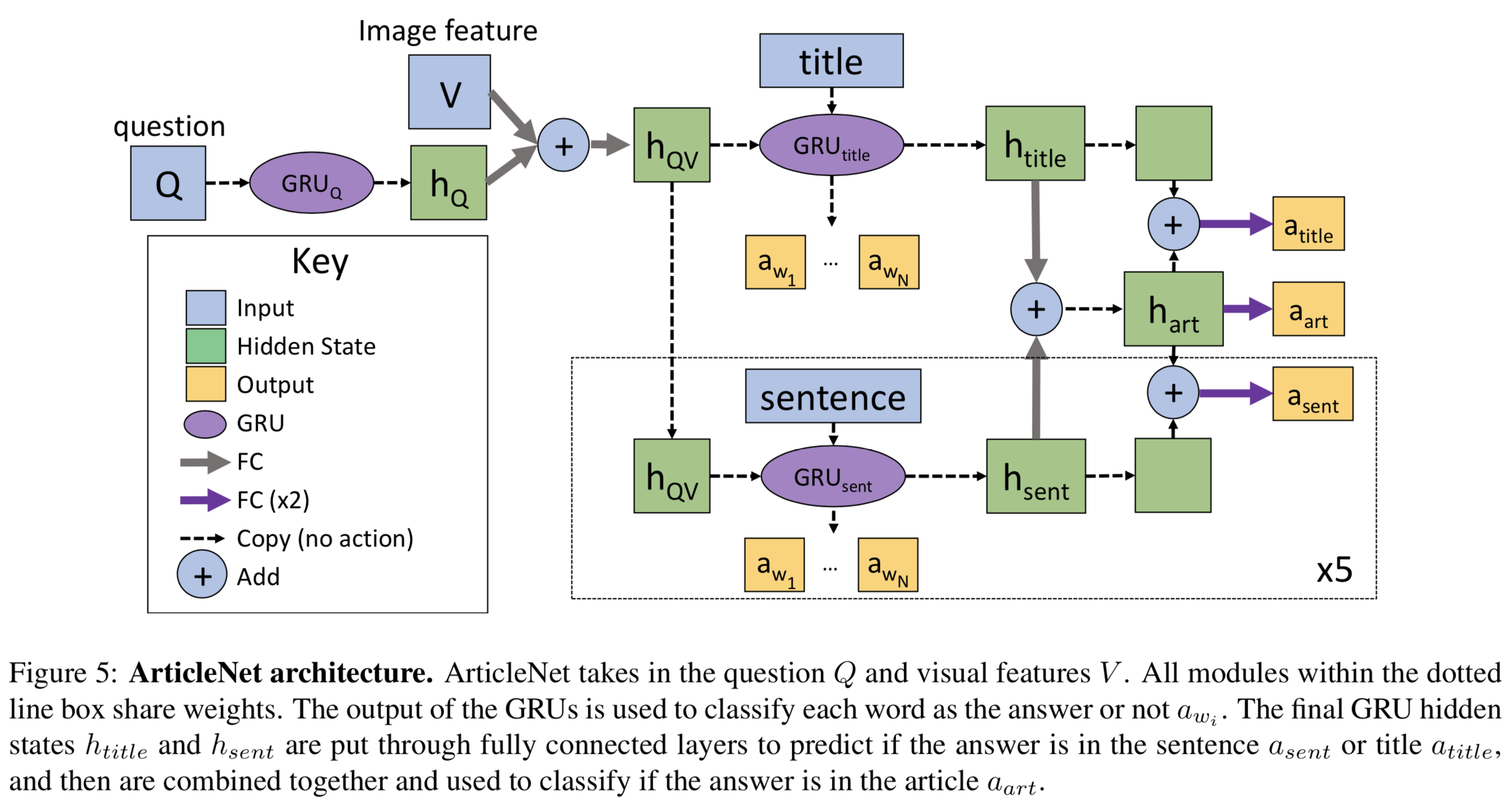
- ArticleNet (AN): We consider a simple knowledge-based baseline that we refer to as ArticleNet. The idea is to retrieve some articles from Wikipedia for each question-image pair and then train a network to find the answer in the retrieved articles.
- Retrieving articles is composed of three steps
- come up with possible queries for each question
- use the Wikipedia search API to get the top retrieved article for each query
- extract a small subset (sentences) of each article that is most relevant for the query
- pick the top scoring word [highest value of a(wi)*a(sent)] among the retrieved sentences to find the answer to a question
- ArticleNet is particularly helpful for brands, science, and cooking categories, perhaps suggesting that these categories are better represented in Wikipedia
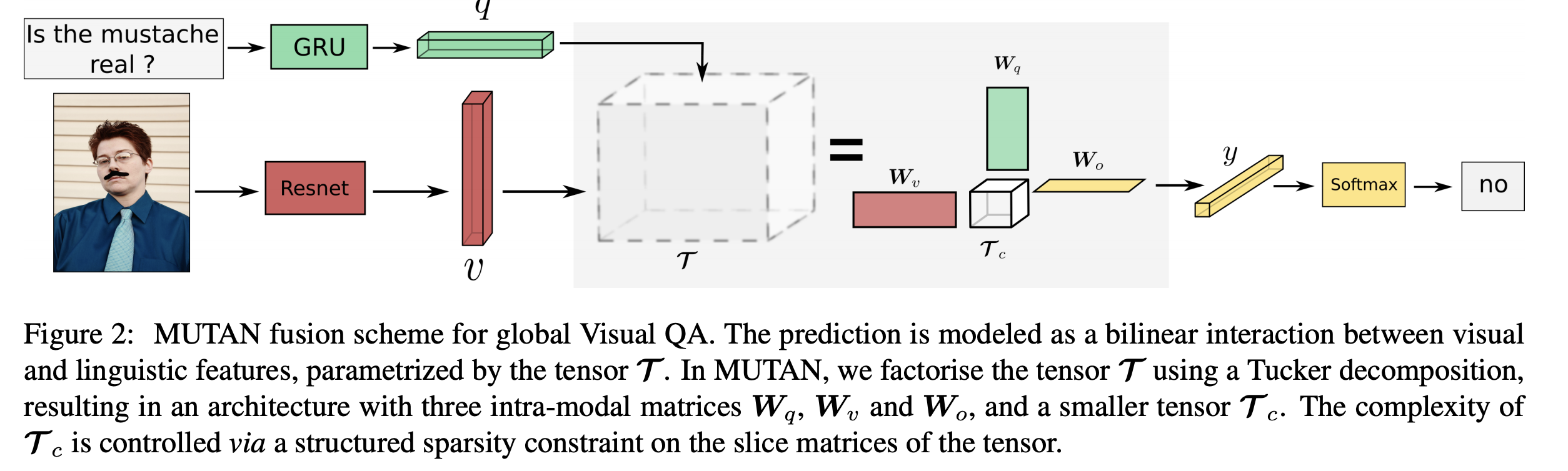
- MUTAN: Multimodal Tucker Fusion (MUTAN) model, a recent state-of-the-art tensor-based method for VQA
- dataset is indeed visually grounded, but better image features do not hugely improve the results –> difficulty lies in the retrieving the relevant knowledge and reasoning required to answer the questions
[CVPR 2016] DenseCap: Fully Convolutional Localization Networks for Dense Captioning
- introduce the dense captioning task, which requires a computer vision system to both localize and describe salient regions in images in natural language
- propose a Fully Convolutional Localization Network (FCLN) architecture that processes an image with a single, efficient forward pass, requires no external regions proposals, and can be trained end-to-end with a single round of optimization (composed of a Convolutional Network, a novel dense localization layer, and Recurrent Neural Network language model that generates the label sequences)
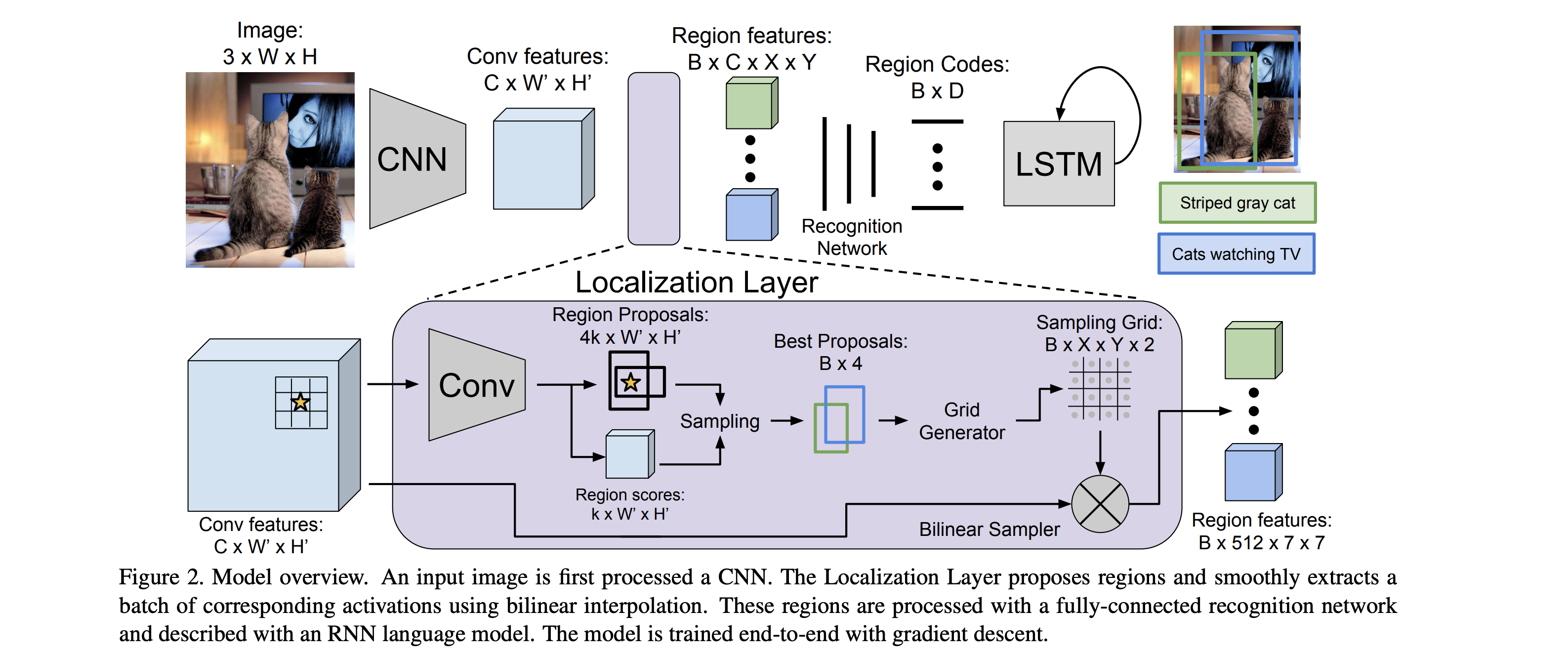
- use the VGG-16 architecture for its state-of-the-art performance
- localization layer is based on that of Faster R-CNN but replace their RoI pooling mechanism with bilinear interpolation
- RoI pooling layer: gradients can be propagated backward from the output features to the input features, but not to the input proposal coordinates –> bilinear interpolation
[ICCV 2015] Faster R-CNN
- complexity arises because detection requires the accurate localization of objects:
- numerous candidate object locations (often called “proposals”) must be processed
- these candidates provide only rough localization that must be refined
- propose a single-stage training algorithm that jointly learns to classify object proposals and refine their spatial locations (jointly optimizes a softmax classifier and bounding-box regressors)
- fast R-CNN has higher detection quality (mAP) than R-CNN, SPPnet; training is single-stage, using a multi-task loss ; training can update all network layers; no disk storage is required for feature caching
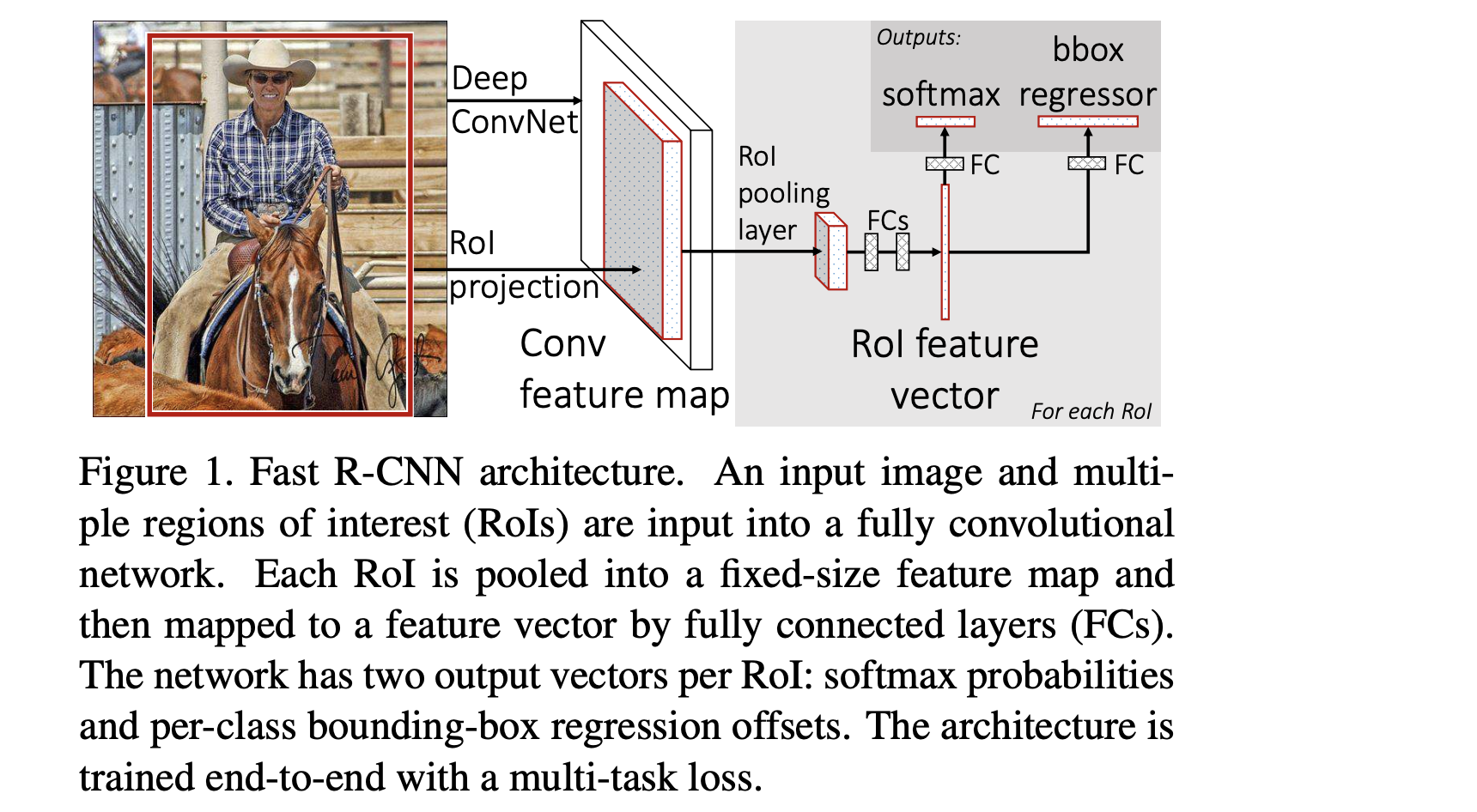
- fast R-CNN network takes as input an entire image and a set of object proposals
- processes the whole image with several convolutional (conv) and max pooling layers to produce a conv feature map
- for each object proposal a region of interest (RoI) pooling layer extracts a fixed-length feature vector from the feature map
- SGD minibatches are sampled hierarchically, first by sampling N images and then by sampling R/N RoIs from each image
- large fully connected layers are easily accelerated by compressing them with truncated SVD
[CVPR 2018] Learning Answer Embeddings for Visual Question Answering
- the key idea is to infer two sets of embeddings: one for the image and the question jointly and the other for the answers
- take the semantic relationships (as characterized by the embeddings) among answers into consideration
- the answer embeddings parameterize a probabilistic model describing how the answers are similar to the image and question pair
- joint embedding function fθ (i, q) to generate the embedding of the pair i and q; an embedding function gφ(a) to generate the embedding of an answer a; decision rule relies on computing fθ(i, q)⊤gφ(a), a factorized form of the more generic function h(i, q, a)
- use two different models to parameterize the embedding function fθ(i,q) in our experiments
- Multi-layer Perceptron (MLP) and Stacked Attention Network (SAN)
- represent each token in the question by 300-d GloVe vector, and use the ResNet-152 to extract the visual features
- For parameterizing the answering embedding function gφ(a), we adopt two architectures:
- utilizing a one-layer MLP on average GloVe embeddings of answer sequences, with the output dimensionality of 1,024
- utilizing a two-layer bidirectional LSTM (bi-LSTM) on top of GloVe embeddings of answer sequences
[CVPR 2016] Learning Deep Structure-Preserving Image-Text Embeddings
- learning joint embeddings of images and text using a two-branch neural network with multiple layers of linear projections followed by nonlinearities
- network is trained using a large margin objective that combines cross-view ranking constraints with within-view neighborhood structure preservation constraints inspired by metric learning literature
- several recent embedding methods are based on Canonical Correlation Analysis (CCA), which finds linear projections that maximize the correlation between projected vectors from the two views –> hard to scale wit large amunts of data
- alternative to CCA is to learn a joint embedding space using SGD with a ranking loss
- in the learned latent space, we want images (resp. sentences) with similar meaning to be close to each other
- the Large Margin Nearest Neighbor (LMNN) approach tries to ensure that for each image its target neighbors from the same class are closer than samples from other classes
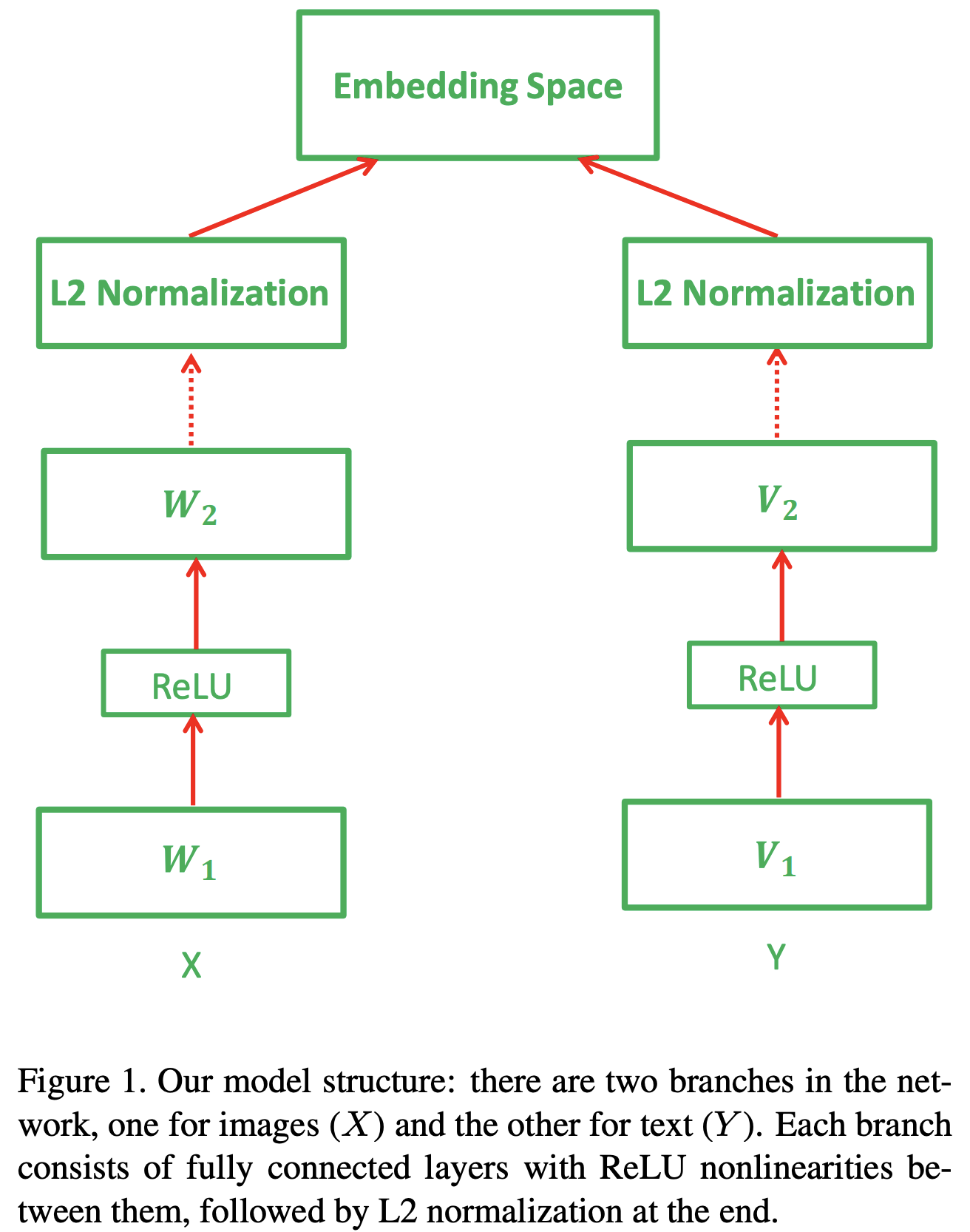
- Bi-directional ranking constraints: the distance between xi and each positive sentence yj to be smaller than the distance between xi and each negative sentence yk by some enforced margin m

- Structure-preserving constraints enforce a margin of m between N(xi) and any point outside of the neighborhood
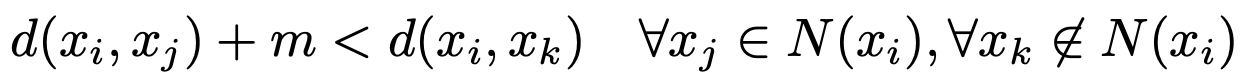
- Embedding Loss Function hinge loss
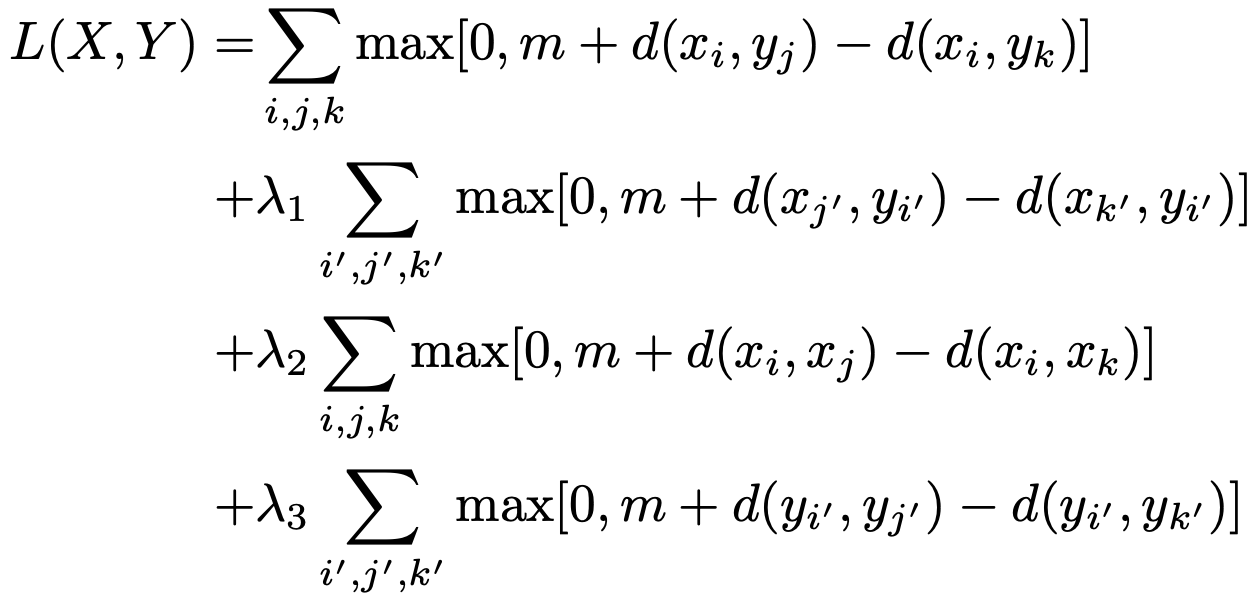
- report results on image-tosentence and sentence-to-image retrieval on the standard Flickr30K and MSCOCO datasets. Flickr30K consists of 31783 images accompanied by five descriptive sentences each. The larger MSCOCO dataset consists of 123000 images, also with five sentences each
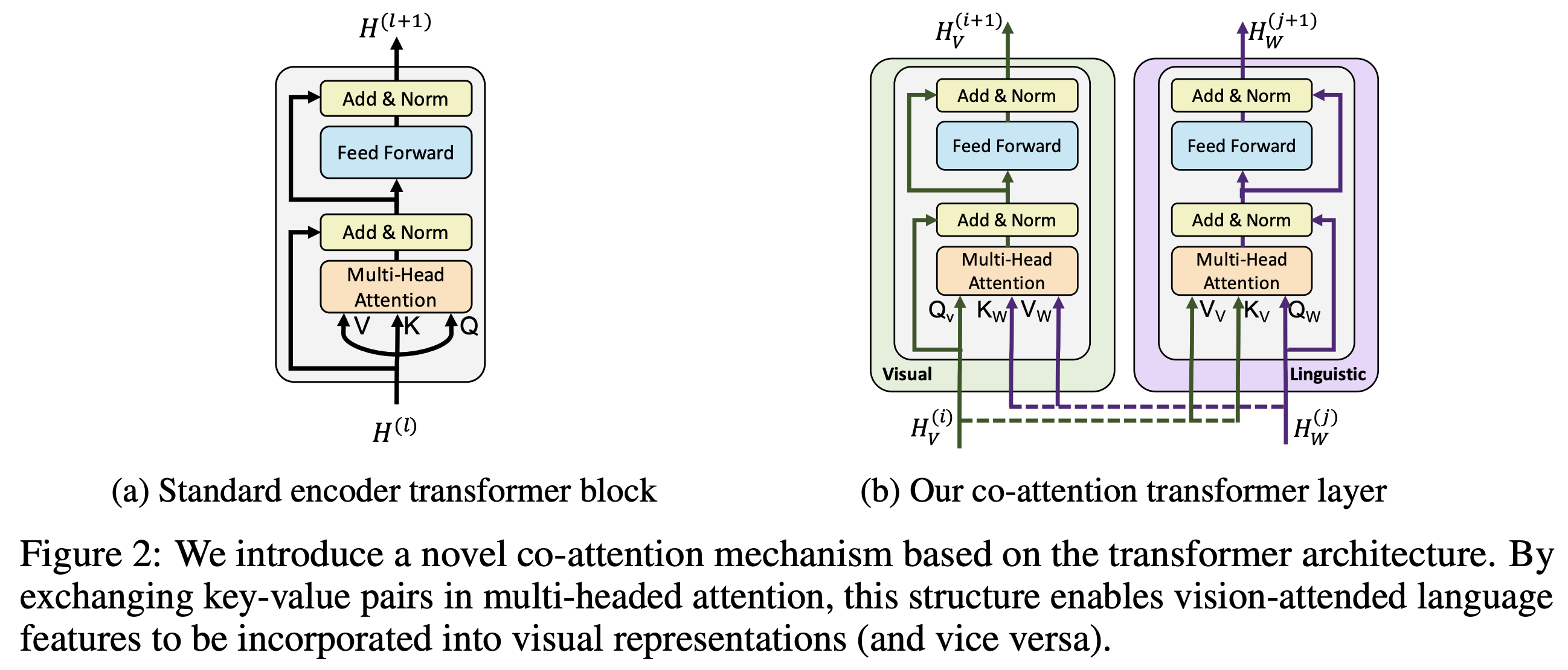
[Arxiv 2019] ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks

- ViLBERT (short for Vision-and-Language BERT), a model for learning task-agnostic joint representations of image content and natural language.
-
extend the popular BERT architecture to a multi-modal two-stream model, processing both visual and textual inputs in separate streams that interact through co-attentional transformer layers
- overall archtitecture
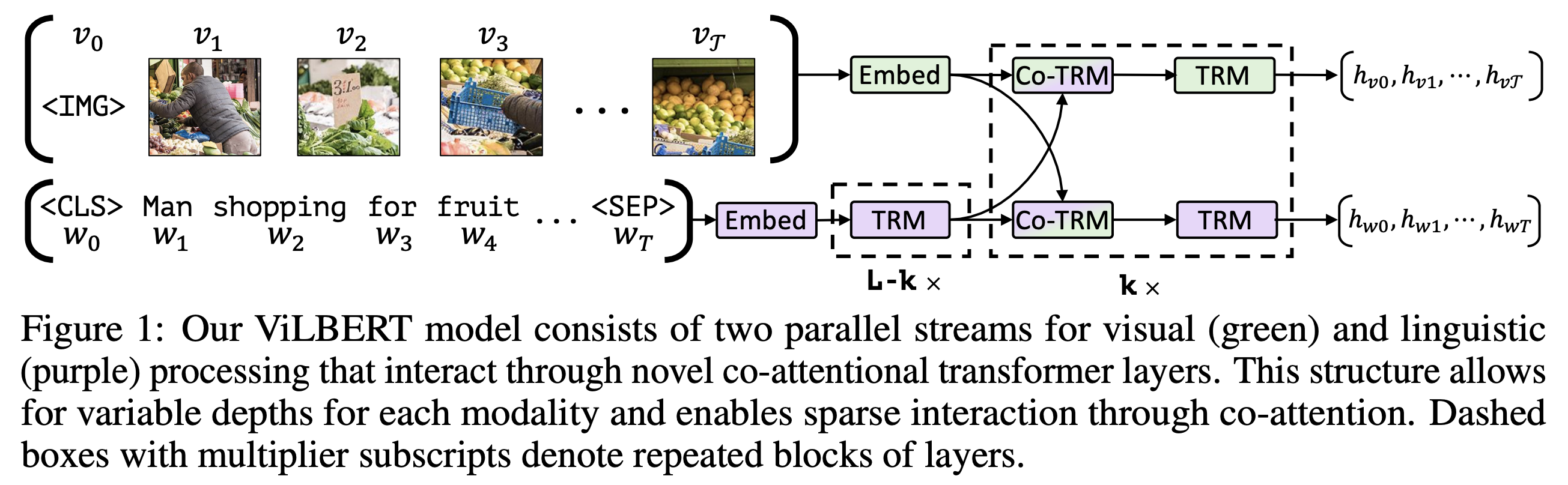
- co-attention transformer
- pretraining tasks for loss
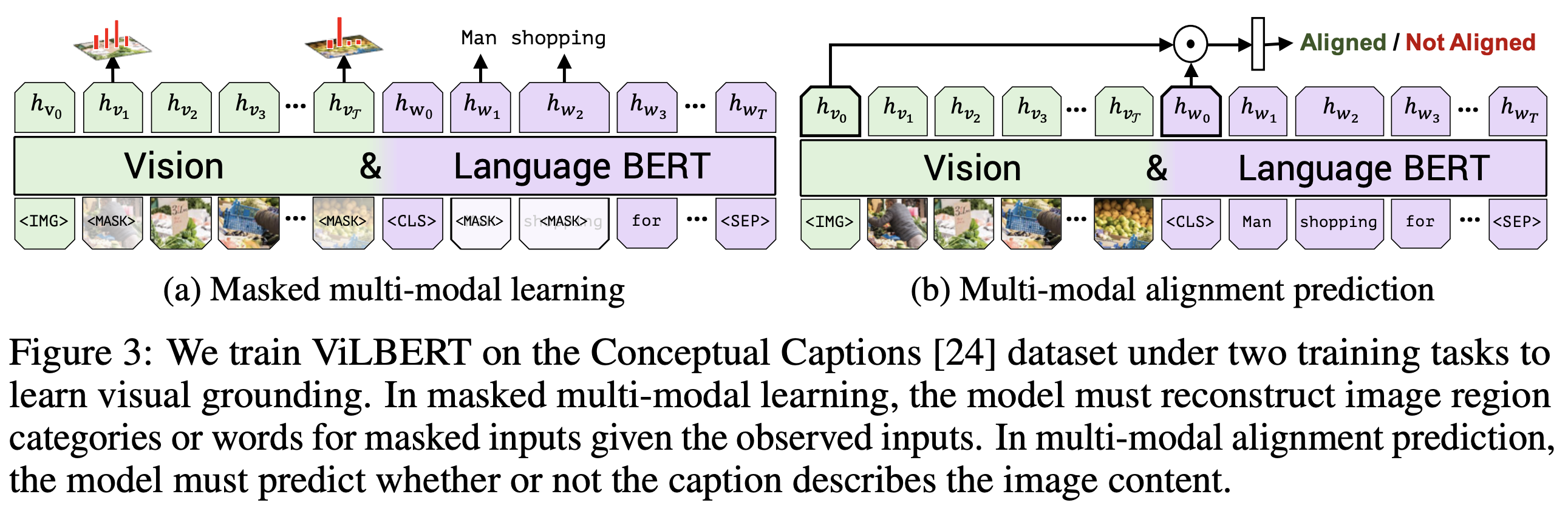
- Downstream tasks
