[INLG 2018] Generation of Company descriptions using concept-to-text and text-to-text deep models: dataset collection and systems evaluation
- study the performance of several state-of-the-art sequence-tosequence models applied to generation of short company descriptions
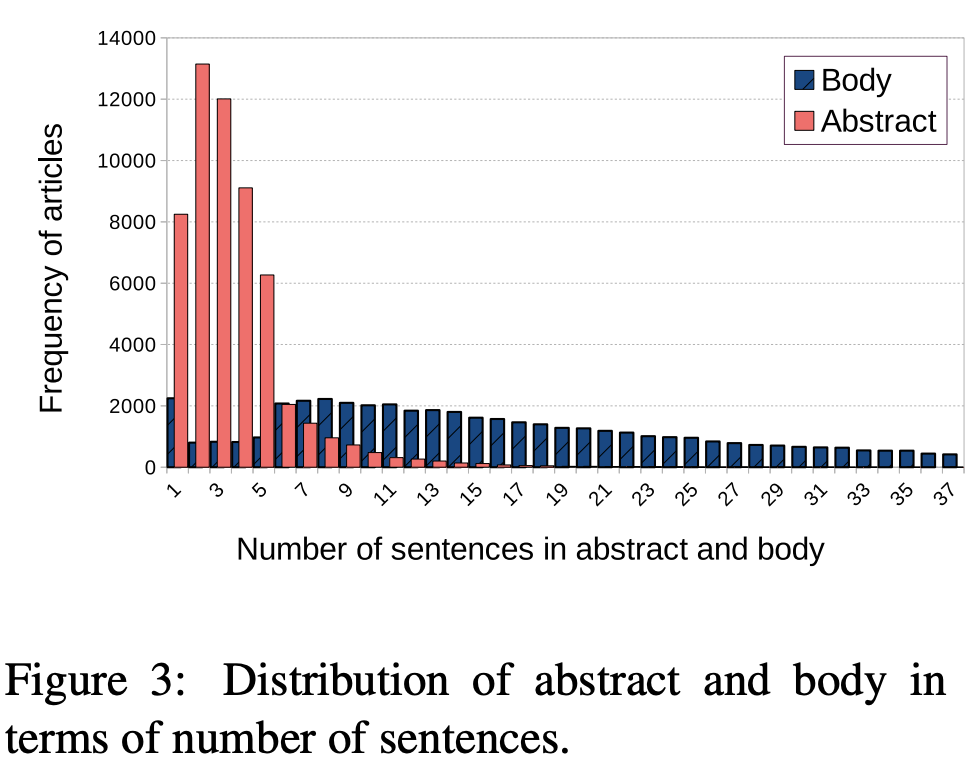
- a newly created and publicly available company dataset that has been collected from Wikipedia, which consists of around 51K company descriptions (Download) that can be used for both concept-to-text and text-to-text generation tasks
- the dataset is not ideal for machine learning since the abstract, the body and the infobox are only loosely correlated
- the basic model used for generating company description is based on the RNN seq2seq model architecture (Sutskever et al., 2014) which is divided into two main blocks: encoder which encodes the input sentence into fixed-length vector, and the decoder that decodes the vector into sequence of words
- as pointed out by (See et al., 2017) the classical seq2seq models suffer from two commonly known problems: repetition of subsequences and wording off-topic
- repetition is caused at the decoding stage, when the decoder relies too much on the previous output leading to infinite cycle; to deal with this problem is to use a coverage mechanism (Tu et al., 2016): used in machine translation, uses the attention weights to penalize the decoder for attending to input that has already been attended to previously
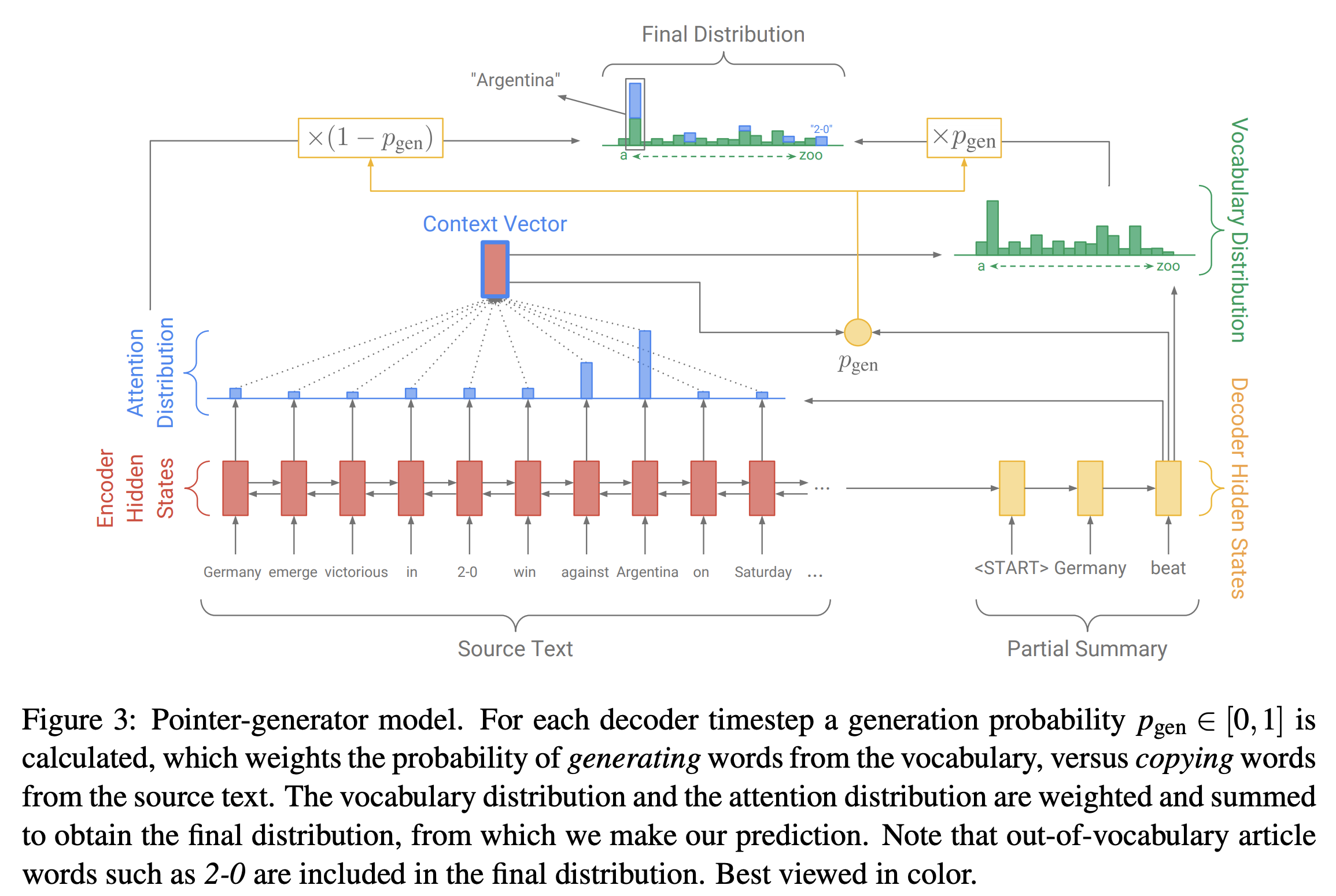
- hallucination can appear when the word to predict is infrequent in the training set and therefore has a poor word embedding making it close to a lot of other words; Pointer-Generator Network (See et al., 2017) which computes a generation probability p_gen ∈ [0, 1]. This value evaluates the probability of ‘generating’ a word based on the vocabulary known by the model, versus copying a word from the source
- standard automatic measures BLEU (Papineni et al., 2002), ROUGE-L (Lin and Hovy, 2003), Meteor (Denkowski and Lavie, 2014) and CIDEr (Vedantam et al., 2015) were computed using the E2E challenge script.
[ACL2019] Multi-Style Generative Reading Comprehension
- reading comprehension (RC) is a challenge task to answer a question given textual evidence provided in a document set
- generative models suffer from a dearth of training data to cover open-domain questions
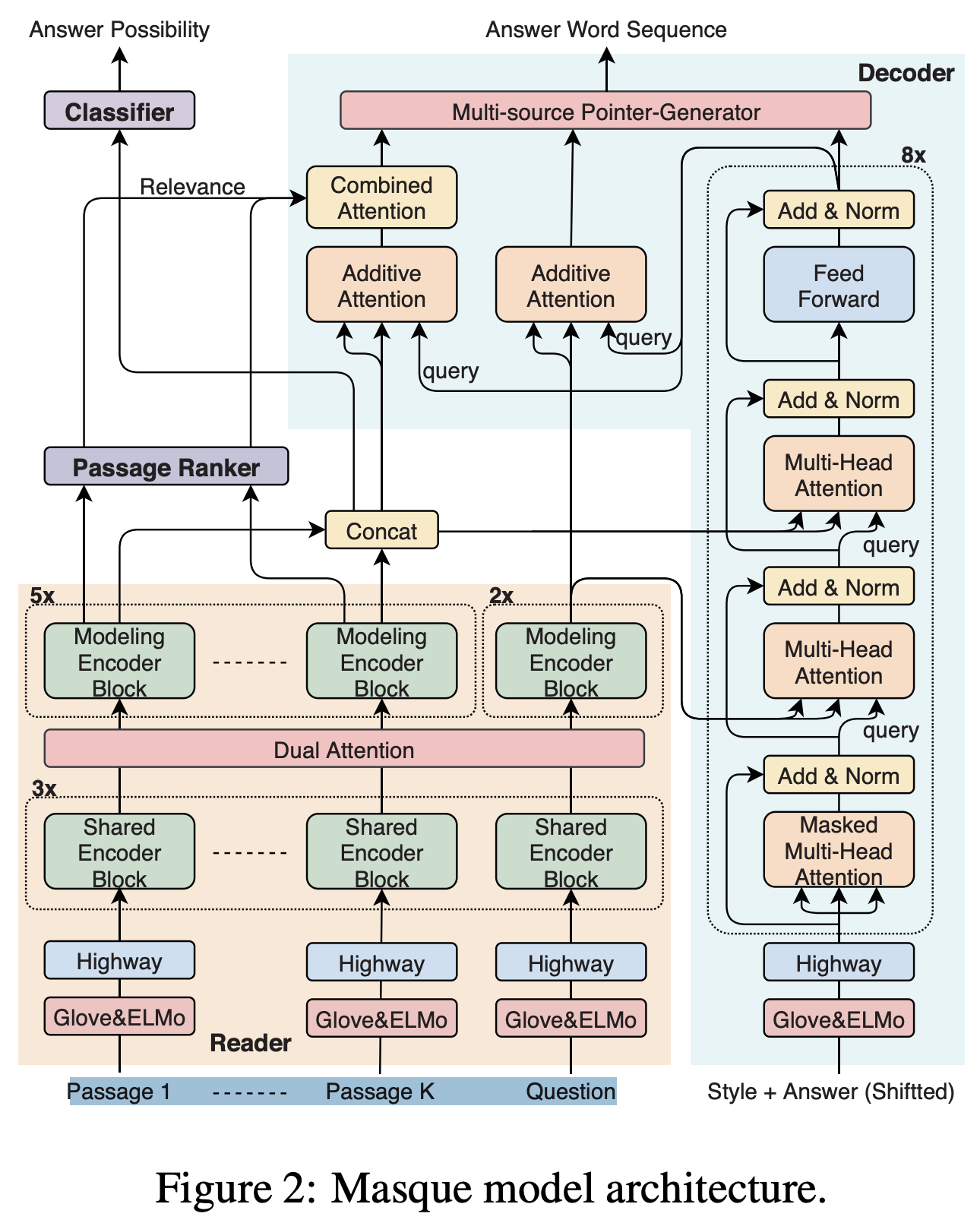
- tackles generative reading comprehension (RC), which consists of answering questions based on textual evidence and natural language generation (NLG)
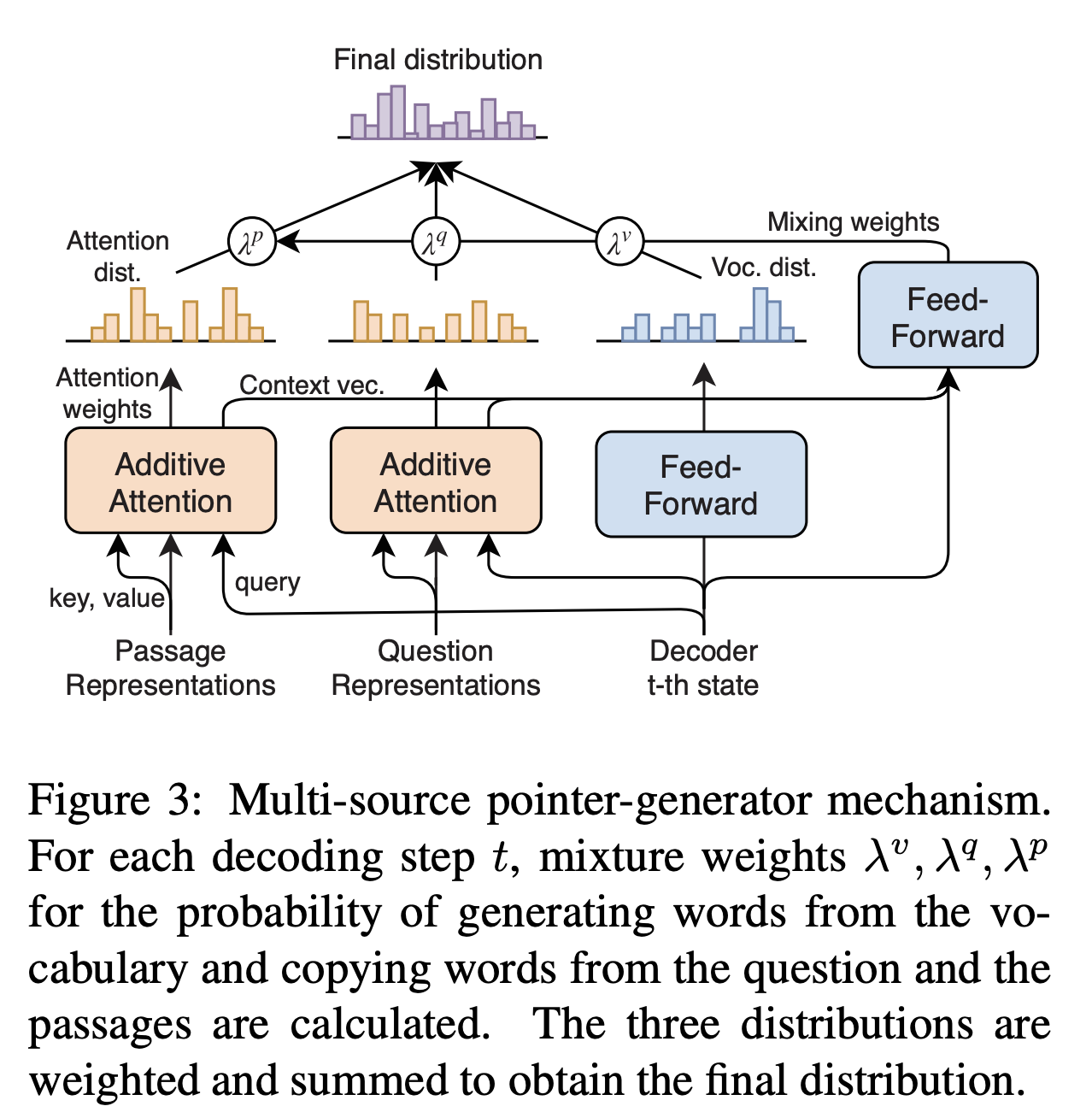
- focuses on generating a summary from the question and multiple passages instead of extracting an answer span from the provided passages –> introduce the pointer-generator mechanism (See et al., 2017) for generating an abstractive answer from the question and multiple passages by extending to a Transformer one that allows words to be generated from a vocabulary and to be copied from the question and passages
- learns multi-style answers within a model to improve the NLG capability for all styles involved –> also extend the pointer-generator to a conditional decoder by introducing an artificial token corresponding to each style
[NAACL2019] Keyphrase Generation: A Text Summarization Struggle
- Problems of most existing keyphrase generation methods:
- First, they are not able to find an optimal value for N (number of keywords to generate for an article) based on article contents and require it as a preset parameter.
- Second, the semantic and syntactic properties of article phrases (considered as candidate keywords) are analyzed separately. The meaning of longer text units like paragraphs or entire abstract/paper is missed.
- Third, only phrases that do appear in the paper are returned. In practice, authors do often assign words that are not part of their article.
- Meng et al. (2017) overcome the second and third problem using an encoder-decoder model (COPYRNN) with a bidirectional Gated Recurrent Unit (GRU) and a forward GRU with attention.
- we explore abstractive text summarization models proposed in the literature, trained with article abstracts and titles as sources and keyword strings as targets.
- Pointer-Generator network (POINTCOV) is composed of an attention-based encoder that produces the context vector. The decoder is extended with a pointer-generator model that computes a probability p_gen from the context vector, the decoder states, and the decoder output.
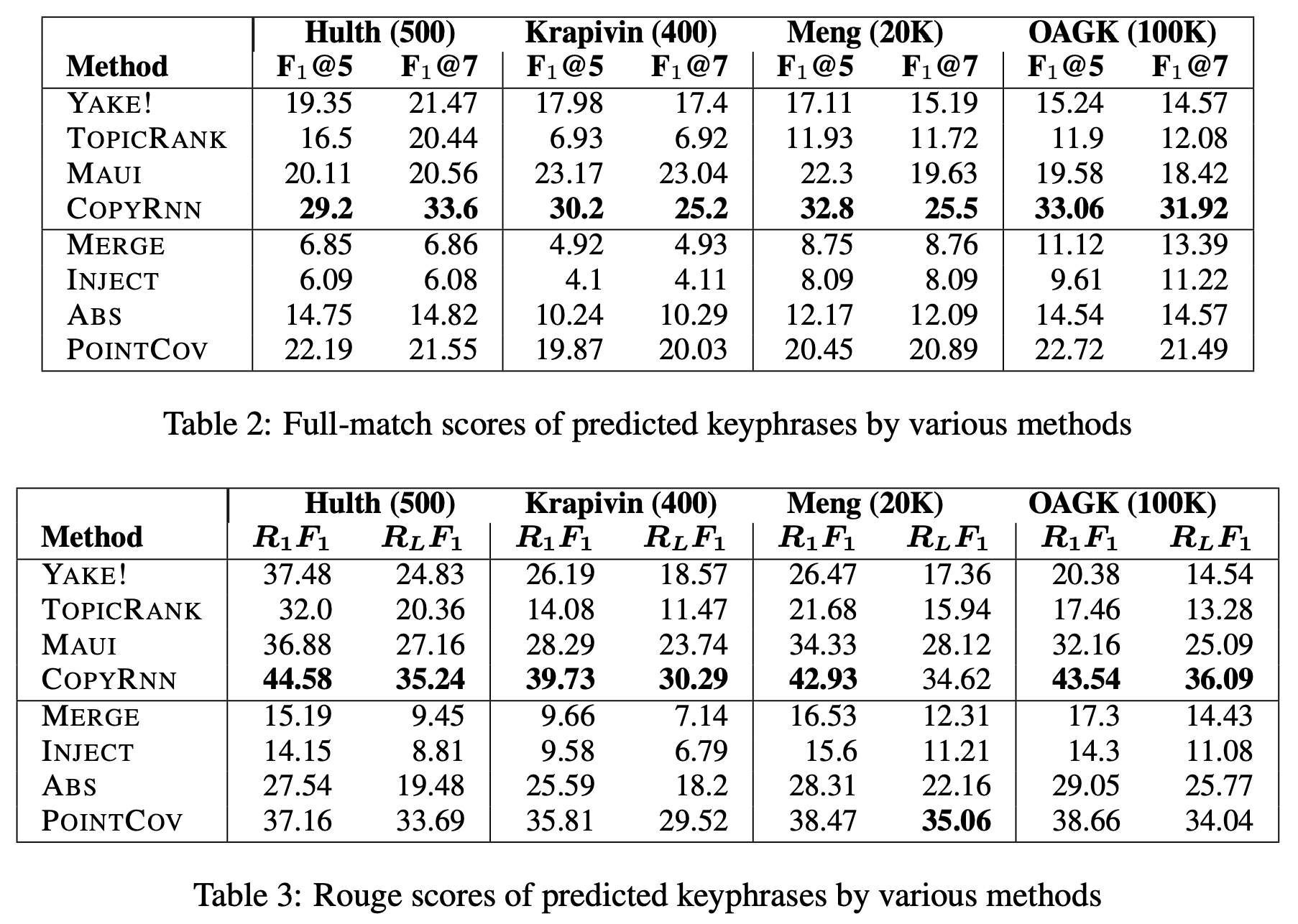
- The results show that the tried text summarization models perform poorly on full-match keyword predictions. Their higher ROUGE scores further indicate that the problem is not entirely in the summarization process.
[ACL 2017] Deep Keyphrase Generation [code]
- propose a generative model for keyphrase prediction with an encoder-decoder framework
- could identify keyphrases that do not appear in the text
- capture the real semantic meaning behind the text
- To apply the RNN Encoder-Decoder model, the data need to be converted into text-keyphrase pairs that contain only one source sequence and one target sequence
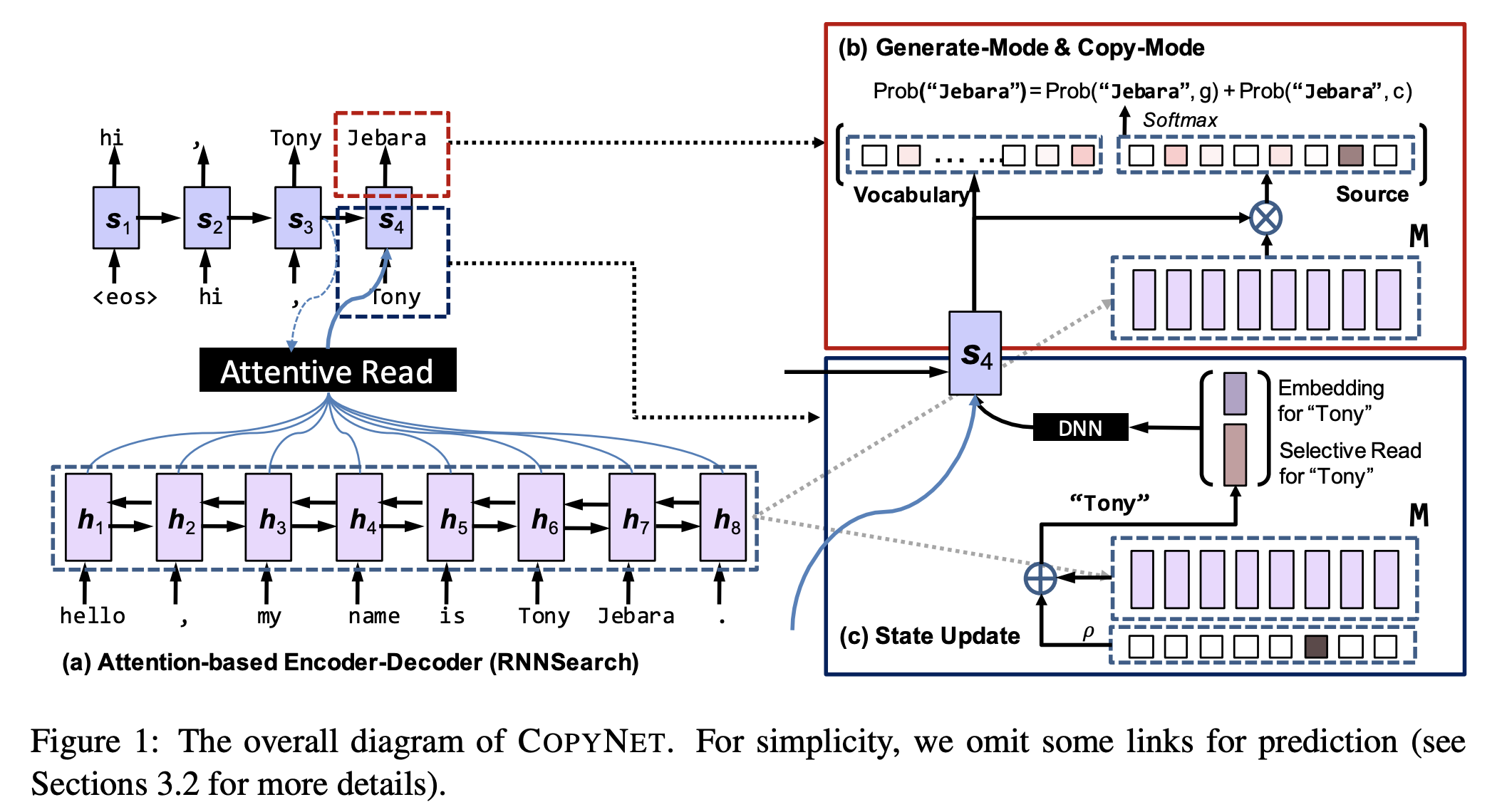
- the RNN is not able to recall any keyphrase that contains out-ofvocabulary words –> copying mechanism (Gu et al., 2016) is one feasible solution that enables RNN to predict out-of-vocabulary words by selecting appropriate words from the source text
[ACL 2017] Get To The Point: Summarization with Pointer-Generator Networks [Tensorflow Python2] [Tensorflow Python3] [Pytorch Python2] [Data Prepossessing]
- Neural sequence-to-sequence models have provided a viable new approach for abstractive text summarization but have two shortcomings:
- they are liable to reproduce factual details inaccurately
- they tend to repeat themselves
- augments the standard sequence-to-sequence attentional model in two orthogonal ways
- copy words from the source text via pointing
- use coverage to keep track of what has been summarized
- Although our best model is abstractive, it does not produce novel n-grams (i.e., n-grams that don’t appear in the source text) as often as the reference summaries. The baseline model produces more novel n-grams, but many of these are erroneous
[SIGIR 2019] DivGraphPointer: A Graph Pointer Network for Extracting Diverse Keyphrases
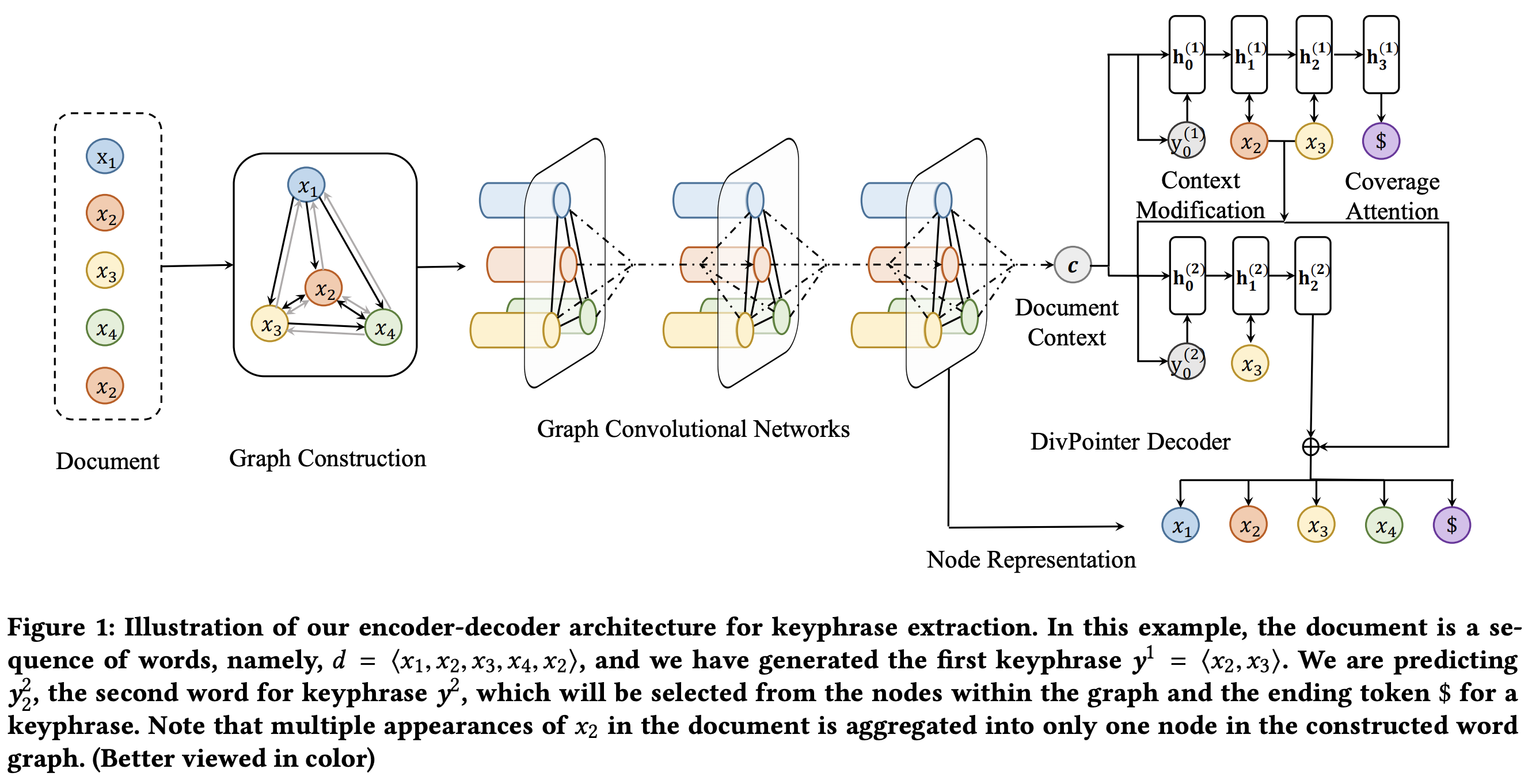
- presents an end-to-end method called DivGraphPointer for extracting a set of diversified keyphrases from a document
- given a document, a word graph is constructed from the document based on word proximity and is encoded with graph convolutional networks
- effectively capture document-level word salience by modeling long-range dependency between words in the document and aggregating multiple appearances of identical words into one node
- propose a diversified point network to generate a set of diverse keyphrases out of the word graph in the decoding process
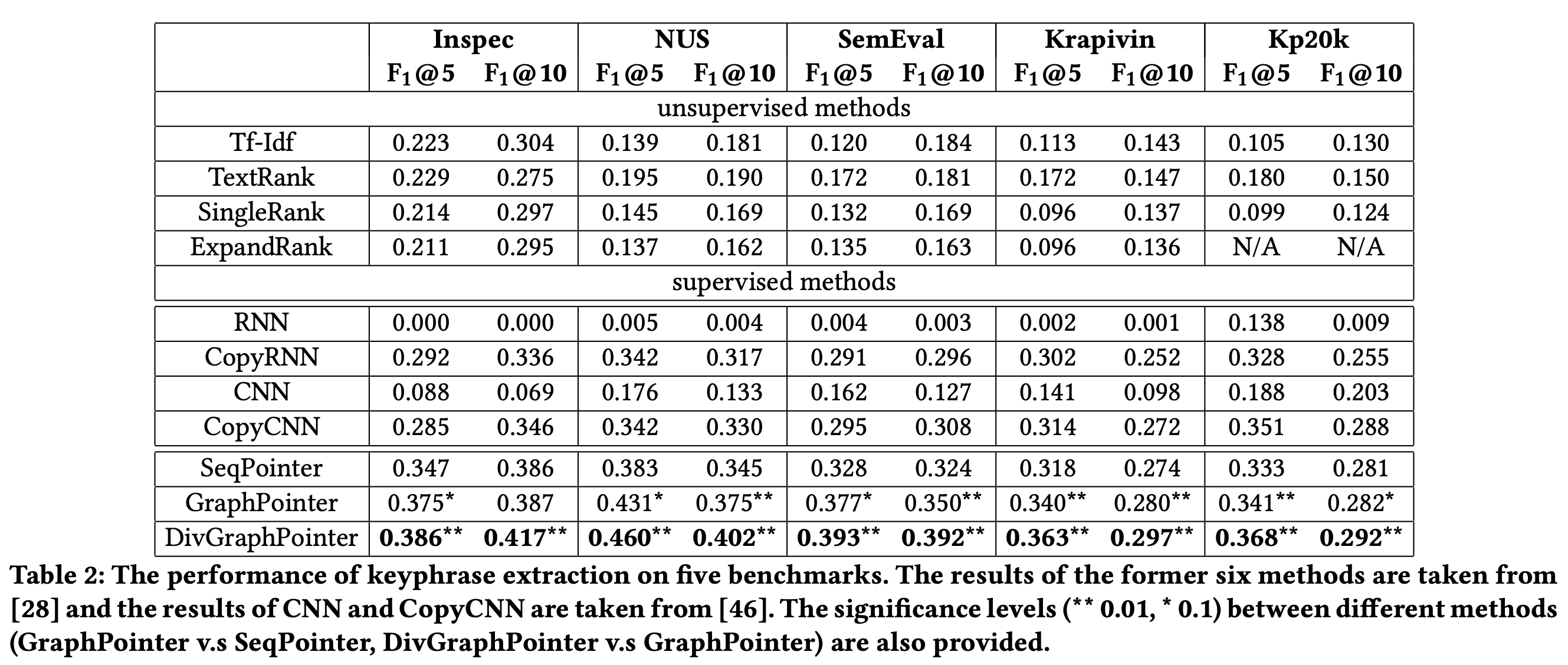
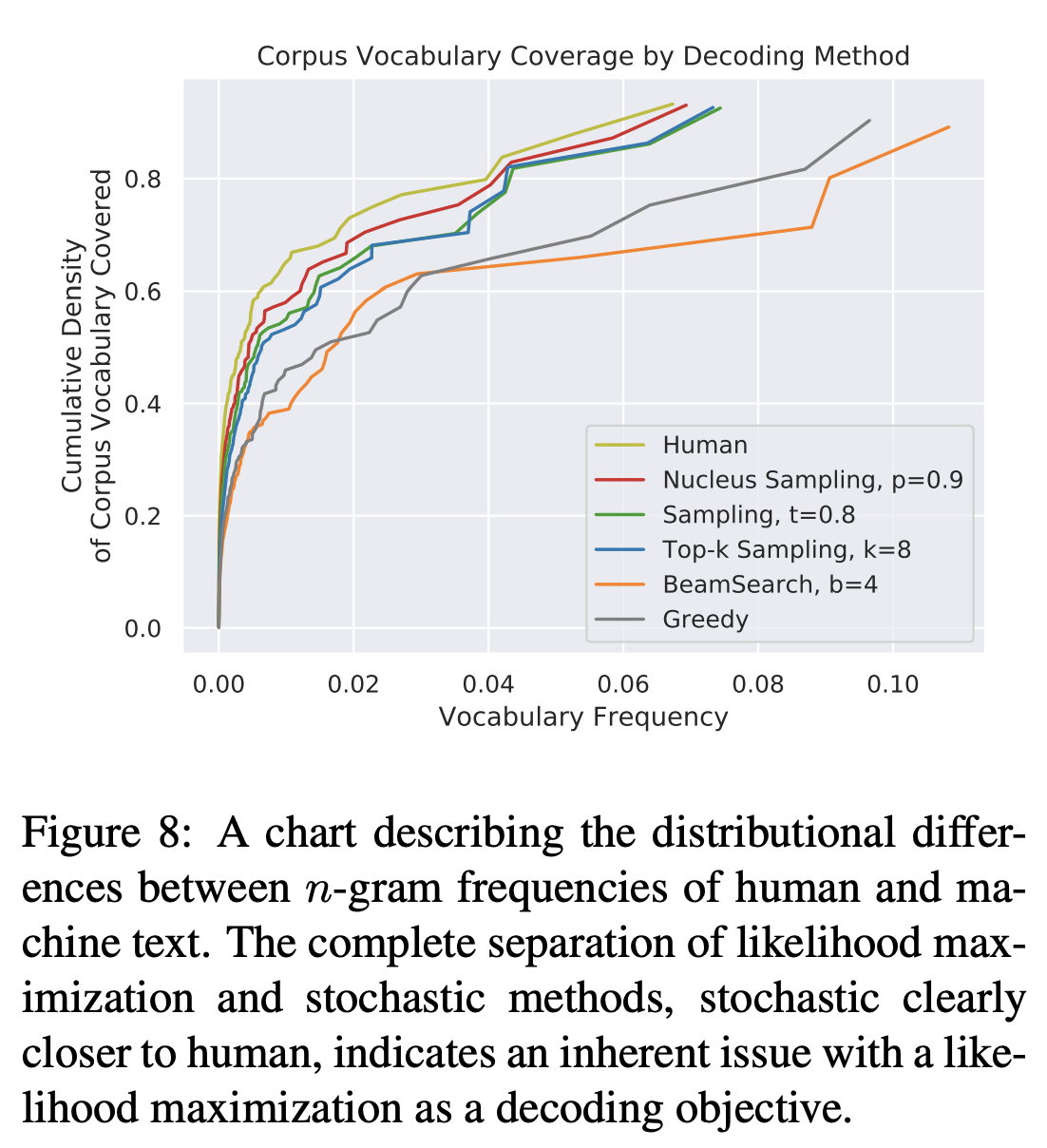
[arxiv19] The Curious Case of Neural Text Degeneration
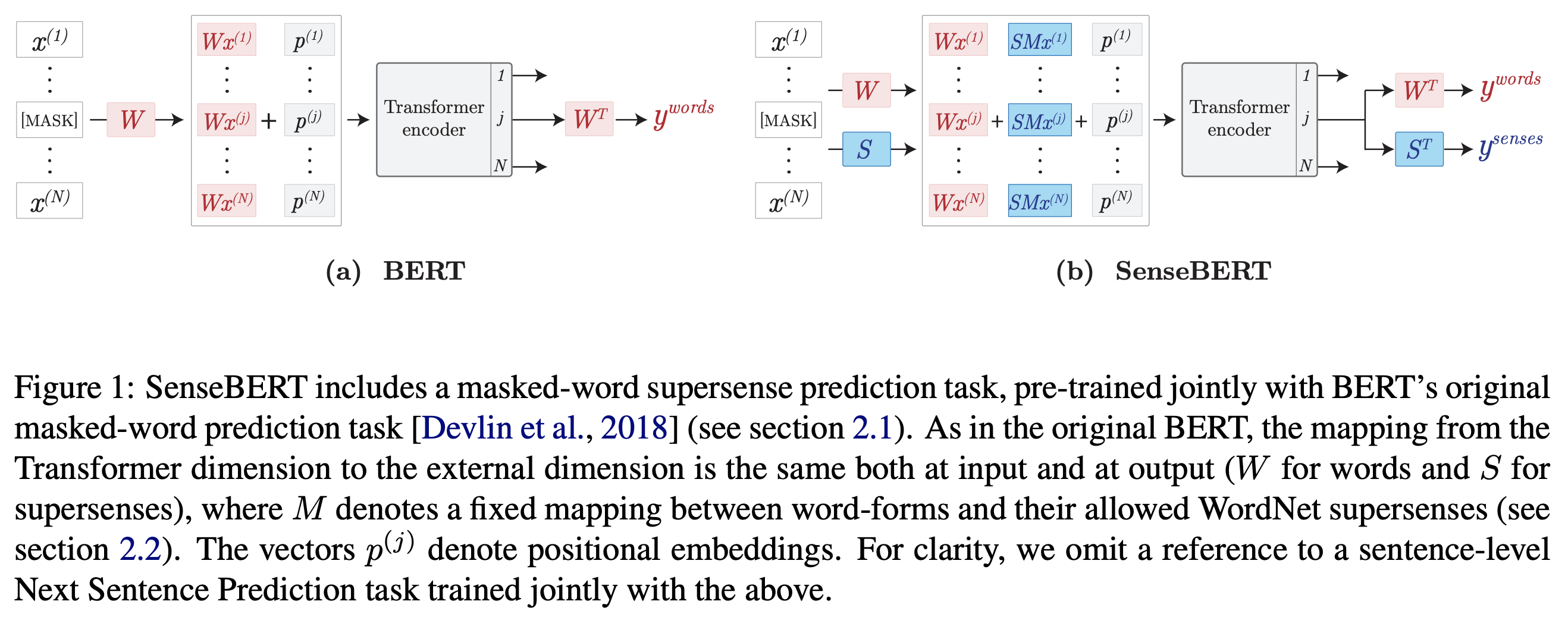
[arxiv19] SenseBERT: Driving Some Sense into BERT
- propose a method to employ selfsupervision directly at the word sense level
- SenseBERT is pre-trained to predict not only the masked words but also their WordNet supersenses –> a lexical-semantic level language model